📝 Paper Summary
Hallucination suppression
Multi-agent
This paper proposes a hallucination detection framework that uses multiple LLM agents (Trust, Skeptic, Leader) engaging in a Markov Chain-based debate to verify claims against retrieved evidence.
Core Problem
Existing hallucination detection methods often rely on simple prompting or static decomposition, neglecting the crucial verification step where errors persist even after accurate claim extraction.
Why it matters:
- LLMs frequently generate inaccurate content (hallucinations), particularly in potent but opaque models like ChatGPT and GPT-4, necessitating reliable detection mechanisms.
- Training-based interventions are expensive and complex, while existing post-processing methods lack the nuance of human-like debate, leading to lower verification accuracy.
Concrete Example:
In a fact-checking procedure, a system might correctly extract a claim and retrieve evidence, but the final verdict stage fails because a single agent simply accepts a plausible-sounding but false claim without rigorous scrutiny or counter-argument.
Key Novelty
Markov Chain-based Multi-agent Debate
- Simulates human debate dynamics where the current discussion state depends on the immediate previous outcome, allowing agents to switch between 'trusting' and 'skeptical' modes.
- Deploys three distinct agent personas (Trust, Skeptic, Leader) that dynamically transition between verifying credibility and challenging inconsistencies until a consensus is reached.
Architecture
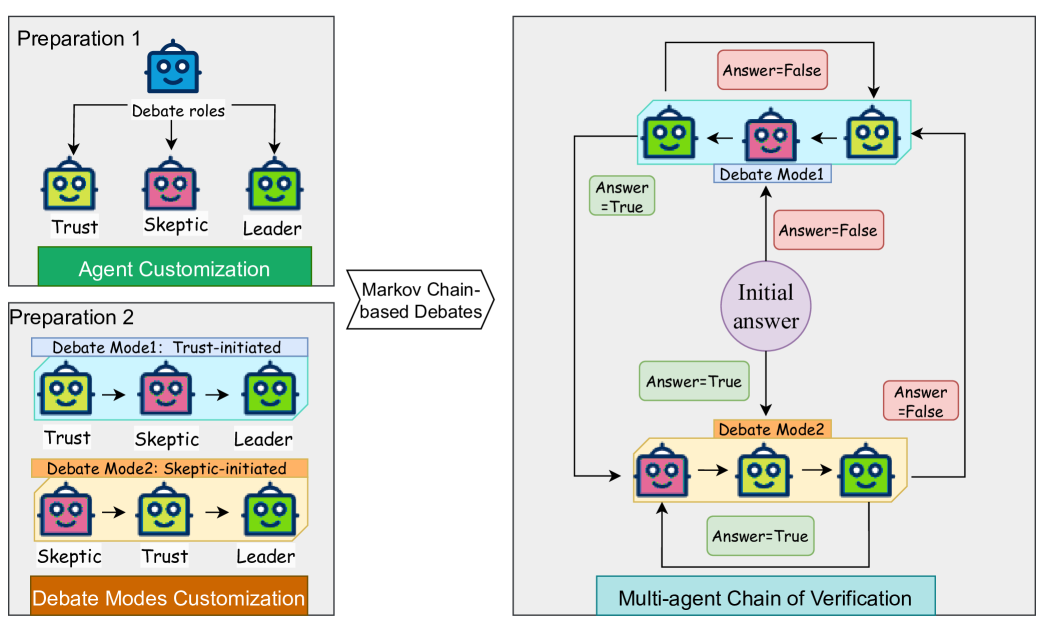
The workflow of the Markov Chain-based multi-agent debate verification framework.
Evaluation Highlights
- Achieves 89.2% accuracy on the HaluEval-Dialogue benchmark, outperforming the standard ChatGPT baseline (84.4%) by +4.8%.
- Outperforms FacTool by +8.6% in accuracy on the HaluEval-QA task (85.6% vs 77.0%).
- Demonstrates superior performance across three distinct generative tasks: Question Answering, Summarization, and Dialogue.
Breakthrough Assessment
7/10
Novel application of Markov Chains to structure multi-agent debates for hallucination detection. Shows consistent improvements over strong baselines like FacTool, though relies on existing LLMs without architectural changes.