📝 Paper Summary
Hallucination Detection
Hallucination Mitigation
Ungrounded Hallucination
CoNLI is a hierarchical framework that detects ungrounded hallucinations using sentence and entity-level Natural Language Inference chains, then uses these judgments to rewrite responses for better factuality.
Core Problem
LLMs frequently generate ungrounded hallucinations—text that conflicts with or cannot be verified against source documents—in text-to-text generation tasks.
Why it matters:
- Business applications like search engines and coding assistants rely on factual consistency, but LLMs are prone to fabricating information.
- Existing detection models (classifiers/rankers) identify errors but do not provide actionable guidance for rewriting or correcting the text.
- Users of third-party LLM APIs often lack control over the model internals (decoding strategies) or cannot access external retrieval tools.
Concrete Example:
If a source text says 'Paris is in France' but an LLM generates 'Paris is in Germany', standard generation models might not catch this conflict. CoNLI would detect 'Germany' as a hallucinated entity and rewrite the sentence to align with the source.
Key Novelty
Hierarchical Chain of Natural Language Inference (CoNLI)
- Decomposes hallucination detection into a hierarchy: first checking full sentences against the source, then zooming in to check specific entities within non-hallucinated sentences to catch subtle errors.
- Uses Chain-of-Thought prompting to guide an LLM to reason through these NLI checks (Entailment vs. Contradiction/Neutral) without needing domain-specific fine-tuning.
- Integrates detection directly with mitigation by using the specific NLI reasoning as instructions for a rewriting agent to correct the text.
Architecture
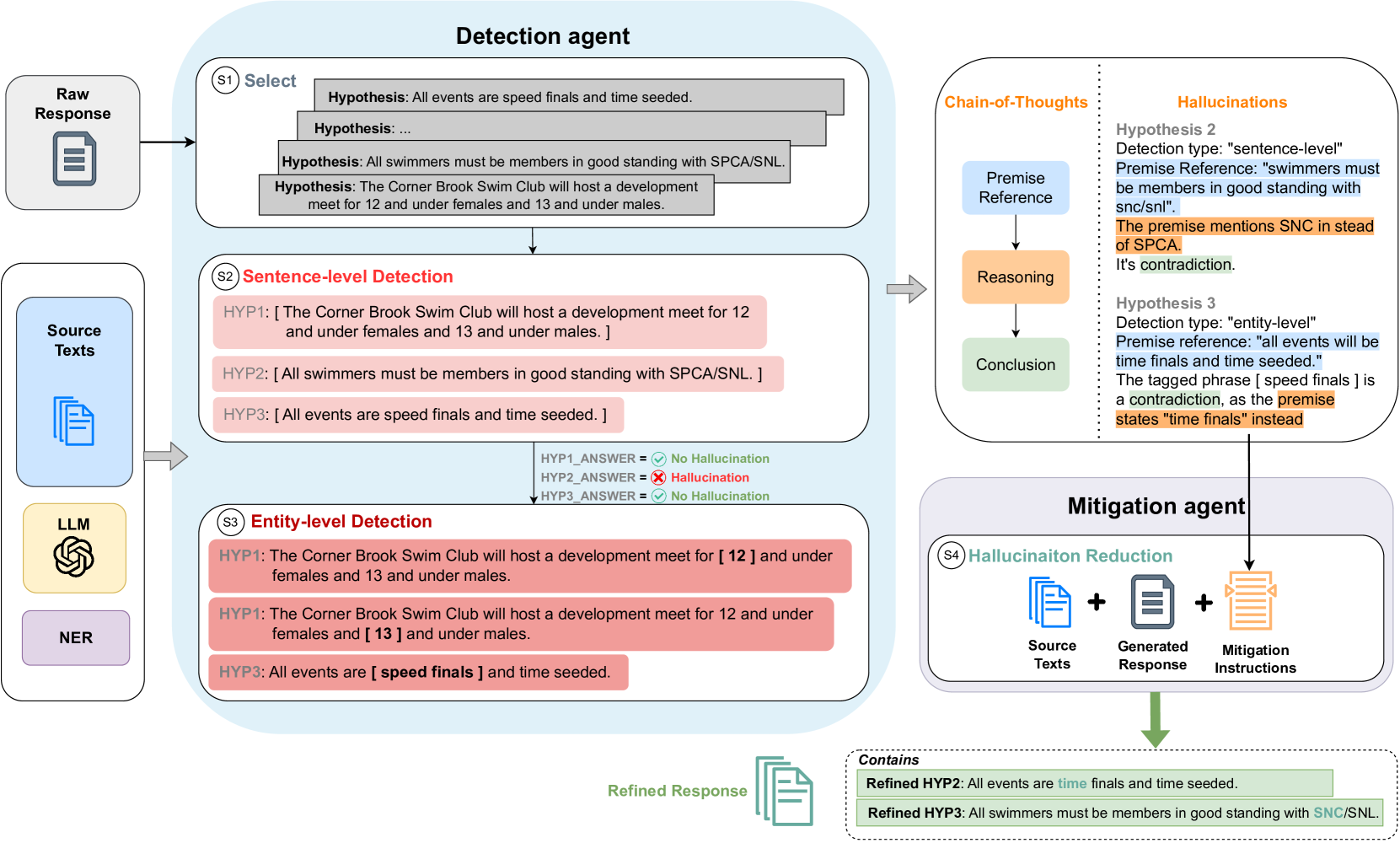
The CoNLI framework workflow comprising the Detection Agent and Mitigation Agent.
Evaluation Highlights
- Achieves state-of-the-art performance on hallucination detection benchmarks compared to latest solutions.
- Refined responses show improvements over initial raw responses on various NLG evaluation metrics and groundedness metrics.
- Demonstrates effectiveness across abstractive summarization and grounded question-answering scenarios without fine-tuning.
Breakthrough Assessment
7/10
Offers a practical, plug-and-play solution for black-box LLM users to reduce hallucinations via post-editing. While methodologically straightforward (NLI + prompting), the hierarchical approach (sentence + entity) addresses a key granularity issue in current detection methods.