📝 Paper Summary
Financial LLM Evaluation
Hallucination Detection
FAITH is an automated framework that evaluates intrinsic hallucinations in financial LLMs by masking numerical spans in annual reports and checking if models can recover them through context-aware reasoning.
Core Problem
Existing hallucination benchmarks rely on general-domain text (e.g., Wikipedia) and simple look-up tasks, failing to capture the complex, context-dependent numerical reasoning required for financial tabular data.
Why it matters:
- Financial decisions rely on precise extraction and calculation from proprietary tables; even minor numerical errors can undermine decision-making and regulatory compliance
- Manual annotation for finance is resource-intensive and unscalable, while current automated methods lack the domain specificity to handle complex financial reasoning patterns
- Undetected hallucinations in automated reporting or investment algorithms can propagate through pipelines, leading to compliance violations or financial losses
Concrete Example:
If a table reports operating income as $500 million, a model might hallucinate 'Operating income was $500 thousand' due to scale confusion, or fail to correctly calculate a year-over-year percentage change explicitly mentioned in the text but derived from table values.
Key Novelty
Context-Aware Masked Span Prediction for Tables
- Treats hallucination evaluation as a fill-in-the-blank task where models must recover masked numerical values in financial text using evidential tables
- Introduces a taxonomy of four financial reasoning types (Direct Lookup, Comparative, Bivariate, Multivariate) to stratify evaluation by complexity
- Implements a 'precision-relaxed' evaluation protocol that normalizes numerical formats (e.g., '$1.2B' vs '1,200 million') to penalize only factual errors, not formatting differences
Architecture
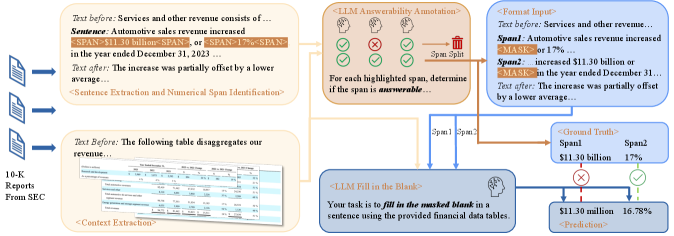
The FAITH framework workflow: from parsing financial documents to masking spans, verifying answerability, and evaluating model predictions
Evaluation Highlights
- Proprietary models (Claude-Sonnet-4, Gemini-2.5-Pro) achieve high overall accuracy but still exhibit 10–20% error rates on multi-step numerical reasoning tasks
- Open-source models fail catastrophically on complex calculations, scoring near zero in multivariate scenarios, highlighting a major gap in reasoning capabilities
- Validation study shows 96.2% accuracy for unanimous LLM consensus in annotating answerability, proving the automated dataset construction is reliable
Breakthrough Assessment
7/10
Strong contribution to domain-specific evaluation, offering a scalable automated method for finance. While methodologically sound, it focuses on evaluation rather than a new model architecture.