📝 Paper Summary
Hallucination Detection
Dialogue Systems
DiaHalu is the first dedicated benchmark for evaluating both factuality and faithfulness hallucinations in multi-turn dialogues across diverse domains, generated naturally by LLMs and manually annotated.
Core Problem
Existing hallucination benchmarks typically focus on non-interactive sentence/passage levels, rely on artificially induced (not naturally generated) hallucinations, and often ignore faithfulness issues like incoherence or self-contradiction.
Why it matters:
- LLMs are widely used in dialogue (chatbots), where unique hallucination types like self-contradiction across turns are critical but under-evaluated
- Most current benchmarks only check if facts align with the world (factuality), neglecting whether the model aligns with user instructions or its own context (faithfulness)
- Artificial triggers in existing datasets do not reflect the natural distribution of errors LLMs make in real-world daily usage
Concrete Example:
In a task-oriented dialogue about booking a train, an LLM might initially say no trains are available, but in the next turn offer a specific train time (faithfulness/consistency hallucination). Current factuality benchmarks would miss this context-conflicting error because they treat sentences in isolation.
Key Novelty
Natural Multi-Turn Hallucination Benchmark
- Simulates natural human-machine interaction by having two LLMs converse (with human alignment for one role) to generate authentic multi-turn contexts
- Expands hallucination taxonomy beyond factuality to include faithfulness subtypes: Incoherence, Irrelevance, Overreliance, and Reasoning Error
- Provides granular annotation at the dialogue level, identifying exactly which turn and subtype exhibits the hallucination
Architecture
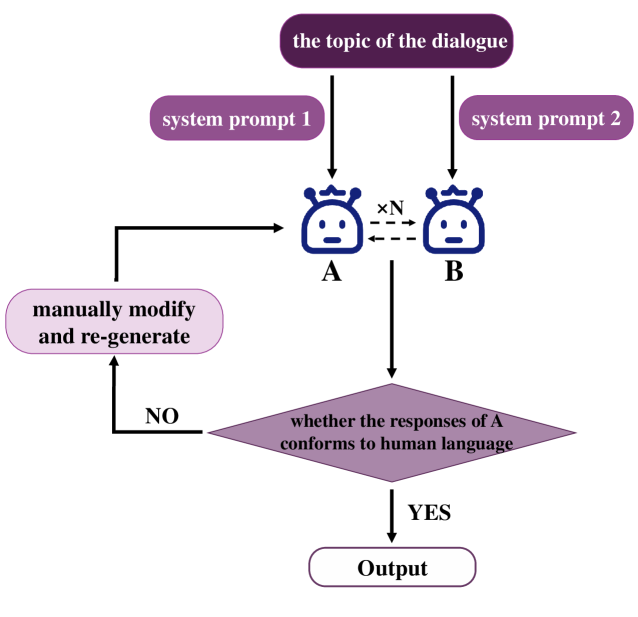
The data construction pipeline for DiaHalu
Evaluation Highlights
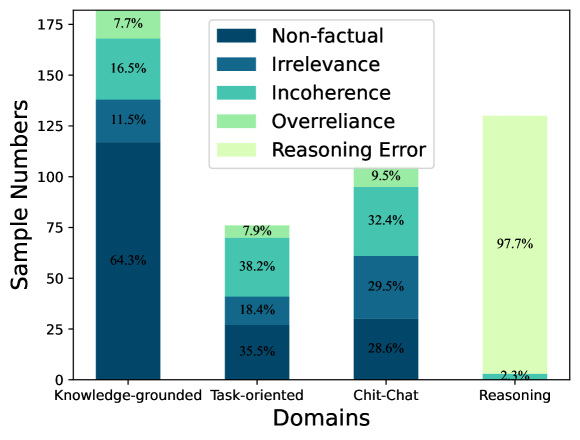
- Hallucination rates are notably high in knowledge-grounded (32.8%) and reasoning (35.2%) dialogues compared to chit-chat (12.4%)
- Faithfulness hallucinations (incoherence, irrelevance) constitute a significant portion of errors in task-oriented and chit-chat scenarios, often dominating factuality errors
- Human annotation achieved an Inter-Annotator Agreement (Fleiss’s Kappa) of 0.8842, indicating high reliability of the dataset labels
Breakthrough Assessment
8/10
Significant contribution as the first dedicated dialogue-level hallucination benchmark covering diverse domains and faithfulness subtypes, filling a clear gap in current evaluation landscapes.