📝 Paper Summary
Hallucination suppression
Factuality detection
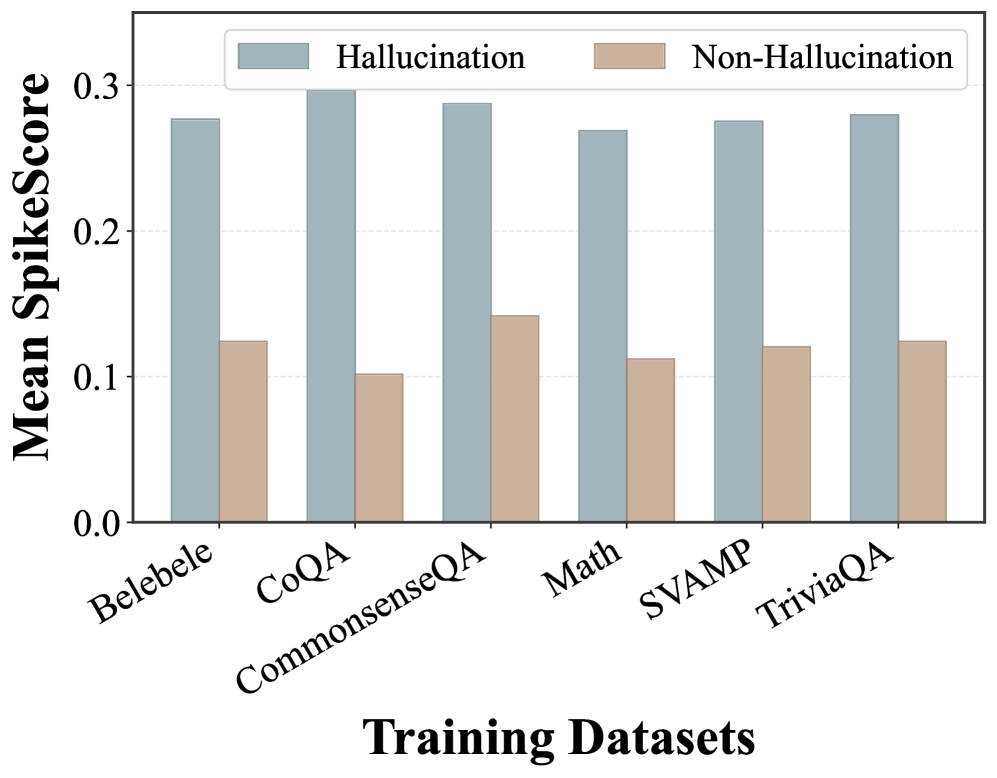
SpikeScore detects hallucinations by measuring abrupt confidence fluctuations in multi-turn dialogues, exploiting the fact that hallucinated answers lead to unstable, self-contradictory trajectories when probed.
Core Problem
Existing training-based hallucination detection methods suffer from poor cross-domain generalization, failing when the test domain distribution shifts from the training domain.
Why it matters:
- Training-based detectors rely on domain-specific features, making them brittle in real-world deployments where test distributions vary (e.g., from commonsense to medical data)
- Hallucinations in high-stakes fields like healthcare and finance undermine trust and safety, requiring robust detection across diverse topics
- Current methods prioritize in-domain separability but neglect the challenge of maintaining that separability consistently across unseen domains
Concrete Example:
A model hallucinates a book author. When asked follow-up questions about the author's other works, the model rapidly contradicts itself or shifts stance, causing its internal confidence scores (SAPLMA) to exhibit sharp 'spikes' (rise and fall). Standard single-turn detectors miss this dynamic instability.
Key Novelty
SpikeScore: Curvature-based Instability Detection in Multi-turn Dialogue
- Constructs a multi-turn 'self-dialogue' by feeding the model's initial answer back as context for follow-up questions
- Quantifies instability using the maximum second-order difference (curvature) of confidence scores along this dialogue path
- Leverages the intuition that hallucinated answers trigger frequent self-correction and stance-shifting when probed, creating distinct 'spikes' in confidence not seen in factual answers
Architecture
Illustration of the multi-turn probing mechanism and the resulting score trajectories.
Evaluation Highlights
- Outperforms state-of-the-art cross-domain methods (PRISM, ICR Probe) in average AUROC across 4 LLMs and 6 benchmarks
- Achieves ~0.775 AUROC on Llama-3.1-8B (average across 5 unseen domains), surpassing the best baseline by significant margins
- Generalizes effectively to RAG pipelines, outperforming baselines on TriviaQA and RAGTruth even when trained only on standard dialogue data (CoQA)
Breakthrough Assessment
8/10
Simple yet theoretically grounded approach that addresses a critical failure mode (generalization). Consistently outperforms complex baselines across diverse models and RAG settings.