📝 Paper Summary
Hallucination mitigation
Data curation for alignment
Knowledge consistency
The paper proposes KCA, a method to mitigate hallucinations by detecting alignment data requiring knowledge the model lacks and then applying strategies like open-book tuning or refusal to resolve the inconsistency.
Core Problem
Fine-tuning foundation models on alignment data containing external knowledge absent from their pretraining corpus creates 'knowledge inconsistency,' leading models to hallucinate plausible but factually incorrect responses.
Why it matters:
- Models forced to align with data they don't 'know' (from pretraining) often fabricate information to satisfy the instruction
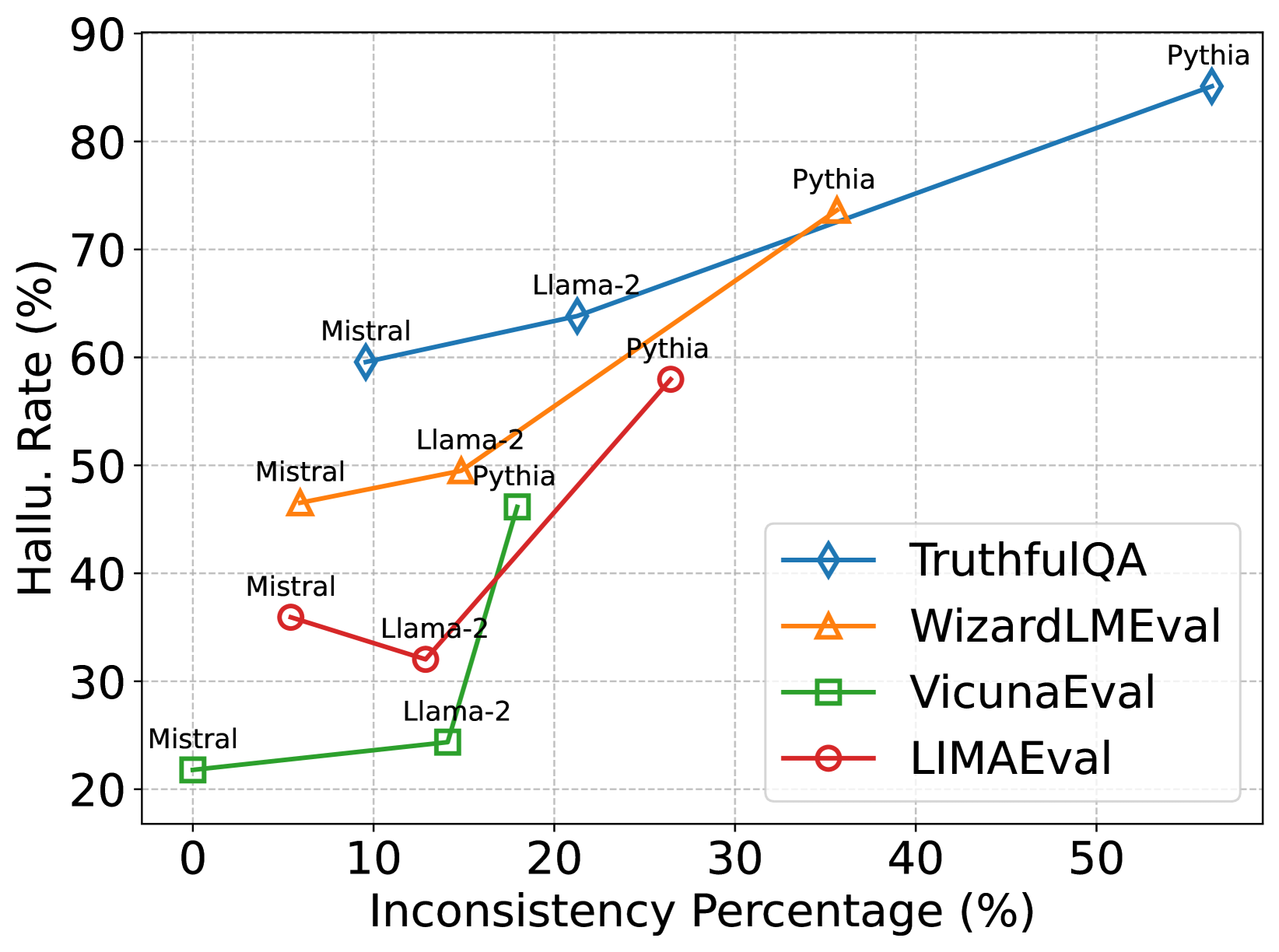
- Existing methods for detecting these boundaries rely on simple QA accuracy, failing on complex tasks (e.g., long-form generation) or lacking interpretability
- Blindly fine-tuning on inconsistent data degrades truthfulness across diverse benchmarks like medical reporting and RAG
Concrete Example:
A foundation model's pretraining corpus lacks information on 'Direct Preference Optimization' (DPO). If the alignment dataset includes a question asking to explain DPO, the model may hallucinate an incorrect explanation during fine-tuning because it lacks the intrinsic knowledge, yet tries to mimic the helpful response style.
Key Novelty
Knowledge Consistent Alignment (KCA)
- Uses a well-aligned helper model (e.g., GPT-3.5) to generate multiple-choice exams based on the specific knowledge required by an instruction, testing if the foundation model actually 'knows' the topic
- Instead of just filtering data, it applies three specific calibration strategies (Open-book, Discard, Refusal) to handle identified knowledge gaps before fine-tuning
- Explicitly generates and utilizes reference knowledge snippets to attribute inconsistencies, rather than relying solely on model confidence scores
Architecture
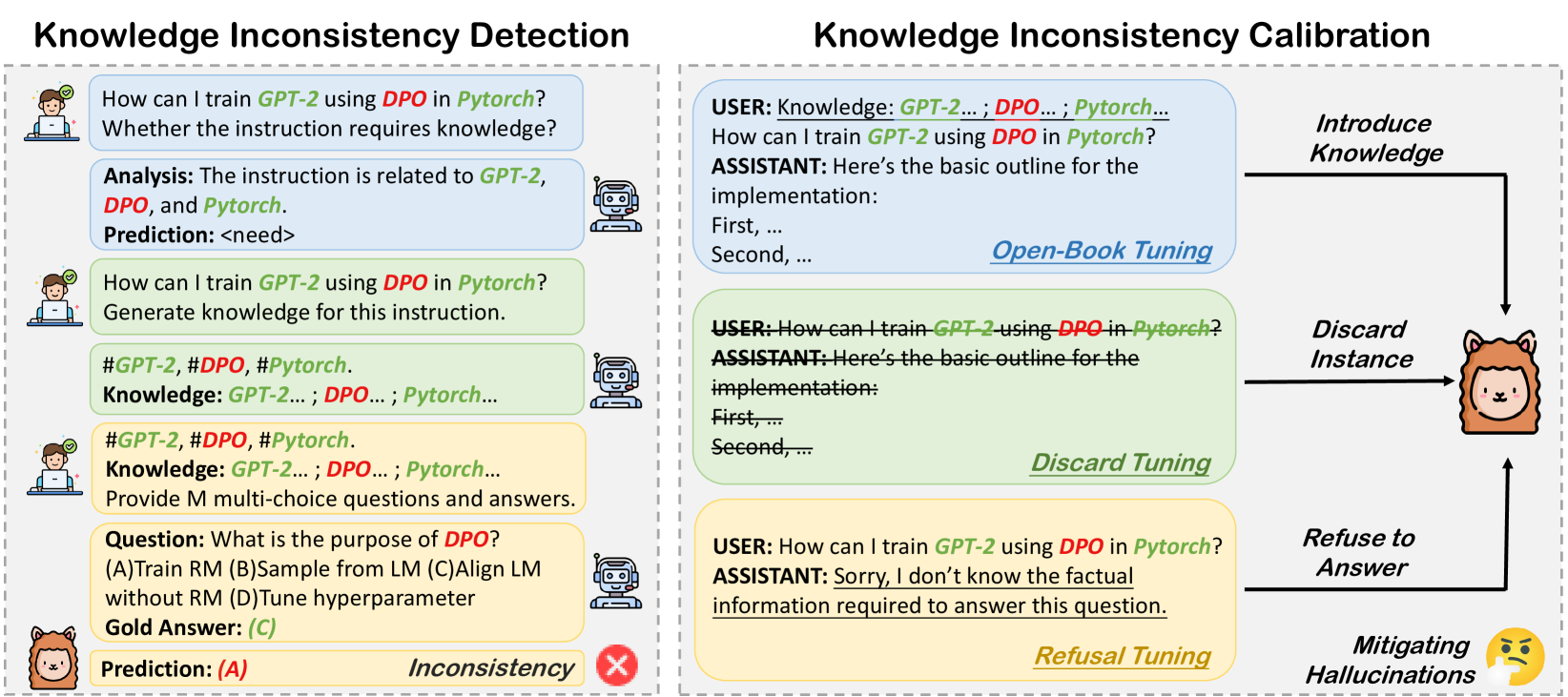
The overall workflow of Knowledge Consistent Alignment (KCA).
Evaluation Highlights
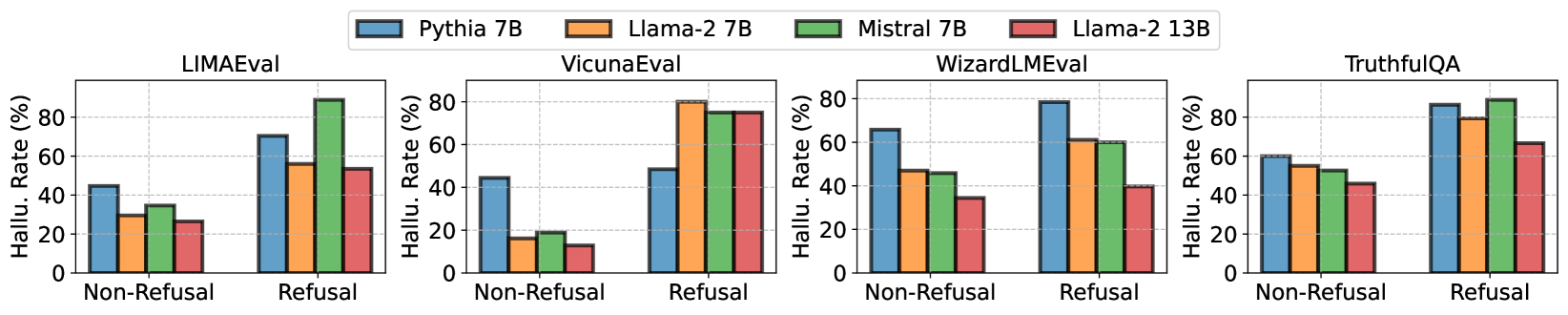
- Reduces hallucination rate by ~5-10% on TruthfulQA compared to standard instruction tuning across Llama-2-7B and Mistral-7B
- Refusal tuning strategy achieves the lowest hallucination rates, while open-book tuning best maintains helpfulness
- Consistent improvements across 6 diverse benchmarks including general instruction following, RAG, and clinical report generation
Breakthrough Assessment
7/10
A solid data-centric approach to hallucination. Shifting the focus from model architecture to ensuring 'knowledge consistency' in training data is practical and effective, though the reliance on a strong teacher model for exam generation is a constraint.