📝 Paper Summary
Faithfulness in Chain-of-Thought
Reasoning Verification
CSR trains models to be faithful by perturbing reasoning steps (like swapping math operators) and penalizing the model if it still outputs the original answer despite the flawed logic.
Core Problem
LLMs often generate correct final answers based on flawed or irrelevant reasoning traces because training objectives reward only the final output, not the logical validity of the steps.
Why it matters:
- Unfaithful reasoning (hallucinated rationales) undermines trustworthiness in high-stakes domains like math, code, and formal logic.
- Post-hoc methods like Chain-of-Thought prompting or self-consistency do not guarantee that the model actually computes the answer using the generated trace.
Concrete Example:
In a math problem ('20 dollars, buys 4 packs at $2 each'), a standard model might output a flawed trace like '20+8=12' (using addition instead of subtraction) yet still predict the correct answer '12', showing it ignored its own reasoning.
Key Novelty
Counterfactual Sensitivity Regularization (CSR)
- Create 'counterfactual' reasoning traces during training by strategically swapping operators (e.g., changing '+' to '-') using a learned editor model.
- Penalize the main model if its answer distribution remains unchanged given the perturbed trace, forcing it to be sensitive to logical errors.
Architecture
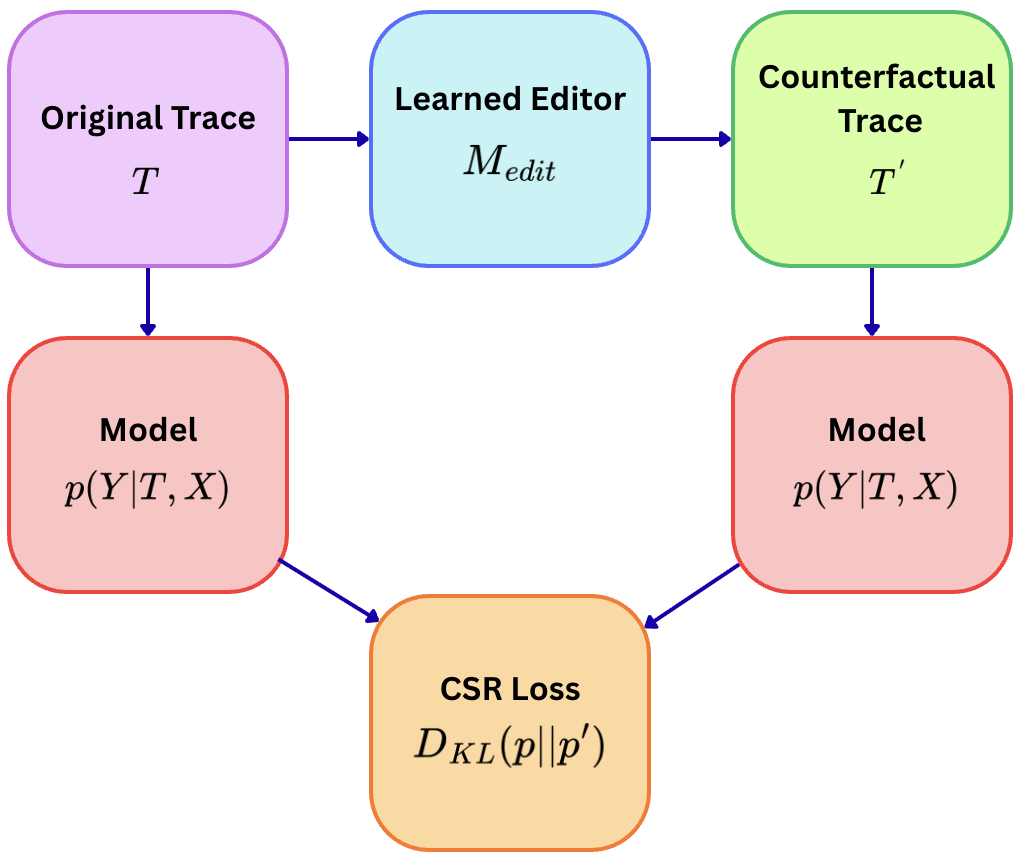
The training pipeline of CSR involving trace generation, editor intervention, and loss calculation.
Evaluation Highlights
- +32.8 to +34.8 point increase in Counterfactual Outcome Sensitivity (COS) on GSM8K and HotpotQA compared to Process Reward Models.
- Achieved 94.2-96.7% operator transfer success across model families, showing learned sensitivity generalizes beyond specific training artifacts.
- Reduced unfaithful-but-correct reasoning rates by 61-68% relative to standard fine-tuning in a manual audit of naturally generated outputs.
Breakthrough Assessment
8/10
Establishes a new Pareto frontier for faithfulness vs. accuracy with a theoretically grounded, training-time intervention that significantly outperforms post-hoc and process supervision baselines.