📝 Paper Summary
Hallucination Detection
Hallucination Correction
Benchmark Datasets
ANAH is a large-scale bilingual benchmark that provides sentence-by-sentence analytical annotations of LLM hallucinations—including reference retrieval, type judgment, and correction—to train superior generative annotators.
Core Problem
Existing benchmarks for LLM hallucinations are often coarse-grained (labeling entire responses without explanation) or outdated (pre-LLM era), making it difficult to trace, analyze, and mitigate specific errors.
Why it matters:
- Hallucinations hinder real-world applications of LLMs, especially in knowledge-intensive tasks, by disseminating misleading information
- Coarse labels (hallucination vs. non-hallucination) fail to identify exactly which sentence is wrong or why (contradictory vs. unverifiable), impeding targeted mitigation
- Detecting hallucinations in fluent, plausible-sounding LLM responses is increasingly difficult for humans and automated systems alike
Concrete Example:
In a generated biography, an LLM might correctly state a person's birth year in sentence 1 but invent a fictional award in sentence 2. Current coarse benchmarks label the whole response 'hallucinated' without distinguishing the correct sentence from the error, whereas ANAH annotates sentence 2 specifically as 'Contradictory Hallucination' with a corrected version.
Key Novelty
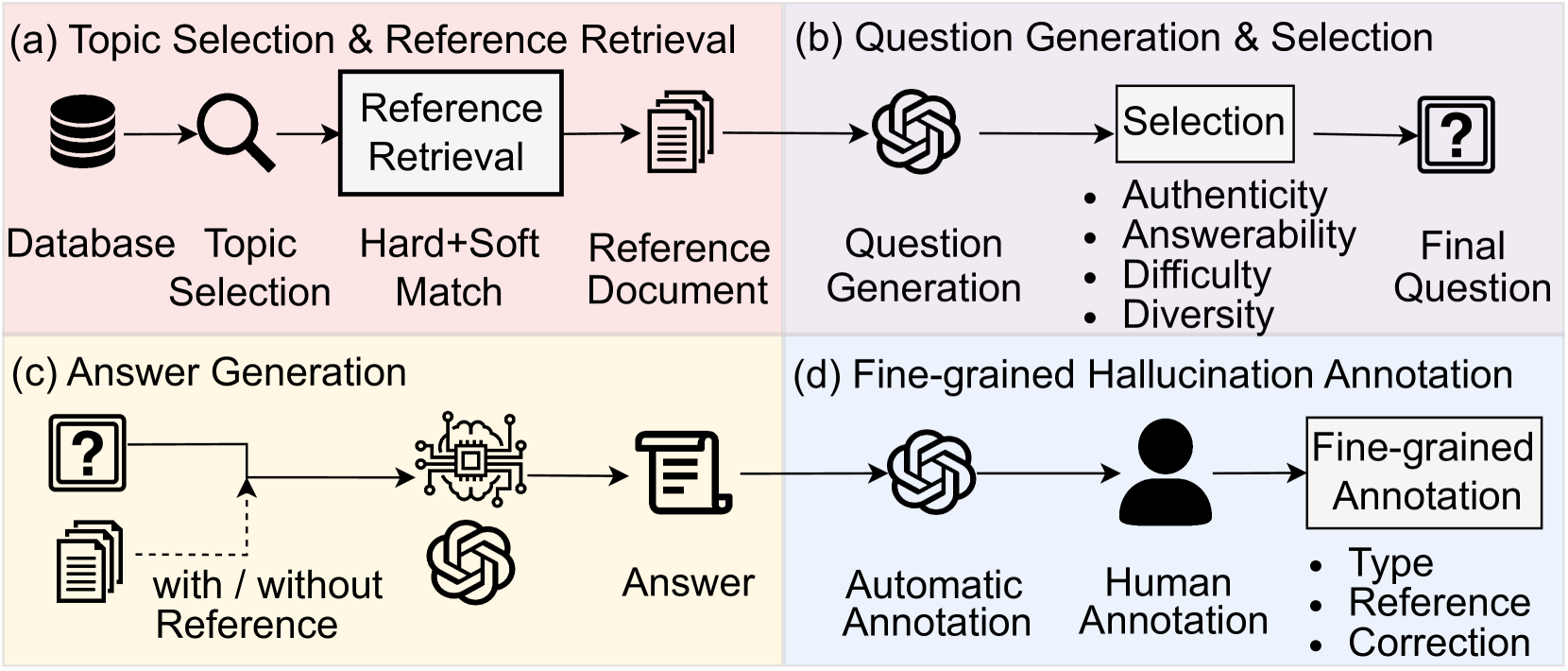
Sentence-Level Analytical Annotation Pipeline
- Constructs a dataset where every sentence in an LLM's answer is annotated with retrieved reference fragments, a specific hallucination type, and a corrected version
- Uses a human-in-the-loop pipeline (GPT-4 preliminary annotation + human verification) to scale high-quality fine-grained data across 700+ topics
- Demonstrates the 'snowball effect' quantitatively: the probability of a hallucination increases significantly if previous sentences were also hallucinations
Architecture
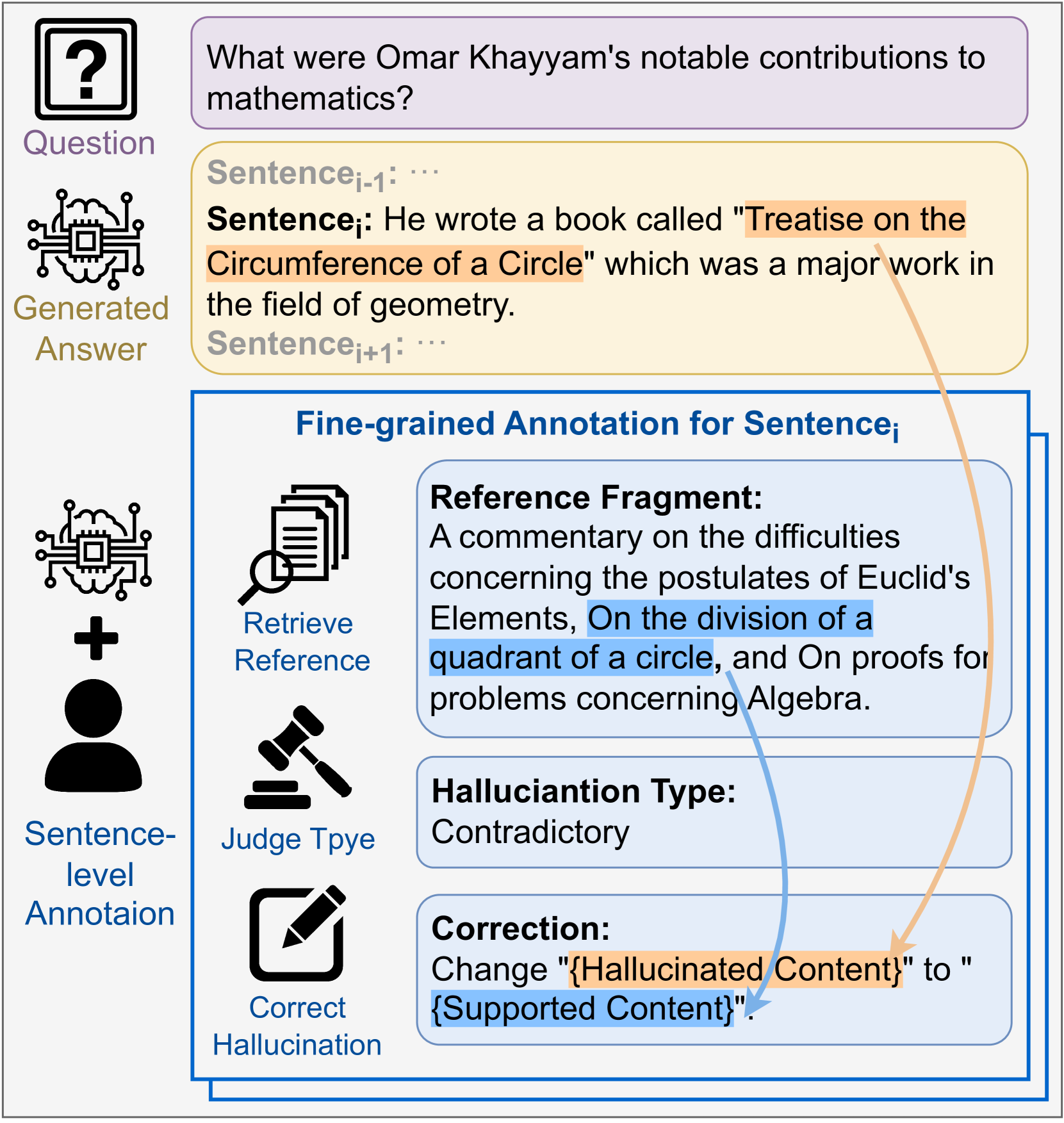
The concept of Analytical Hallucination Annotation, comparing coarse-grained labeling (whole response) with fine-grained analytical annotation (sentence-level)
Evaluation Highlights
- Generative annotator trained on ANAH achieves 81.01% accuracy, surpassing GPT-3.5 and all open-source models
- Generative annotator performance is competitive with GPT-4 (86.97% accuracy) while being smaller and more cost-effective
- Quantitatively confirms hallucination accumulation: Hallucination probability jumps from ~15% to ~55% if previous sentences contained hallucinations
Breakthrough Assessment
8/10
Significant contribution to fine-grained hallucination analysis. The dataset enables training smaller models to detect errors with GPT-4-level performance, addressing a critical measurement gap.