📝 Paper Summary
Hallucination suppression
Factuality in specific domains
The paper empirically quantifies severe hallucinations in LLMs on financial tasks and demonstrates that prompt-based tool learning and RAG are more effective mitigations than few-shot prompting or decoding strategies.
Core Problem
General-purpose LLMs frequently generate unsupported or factually incorrect content (hallucinations) in financial tasks, which carries high risks like monetary loss and erosion of trust.
Why it matters:
- Finance requires pinpoint accuracy; inaccuracies in stock prices or terminology can lead to severe real-world consequences like financial loss
- There is a lack of empirical investigation into how often and to what extent LLMs hallucinate specifically within the intricate financial domain
- Standard mitigation methods like few-shot learning may improve format following but fail to correct fundamental factual errors in domain-specific tasks
Concrete Example:
When asked for the stock symbol of 'Perfumania Holdings', GPT-4 incorrectly provides 'PERF', failing to account for its delisting. Additionally, Llama-2-7B predicts historical stock prices with a mean absolute error of over $6000 in zero-shot settings.
Key Novelty
Empirical Benchmark for Financial Hallucinations
- Establishes a three-task benchmark (acronym recognition, term explanation, stock price query) to quantify hallucinations in finance
- Evaluates the comparative efficacy of four mitigation strategies: few-shot prompting, Decoding by Contrasting Layers (DoLa), RAG, and prompt-based tool learning
- Demonstrates that domain-specific fine-tuning (FinMA) can paradoxically reduce general instruction-following abilities, leading to more hallucinations compared to base models
Architecture
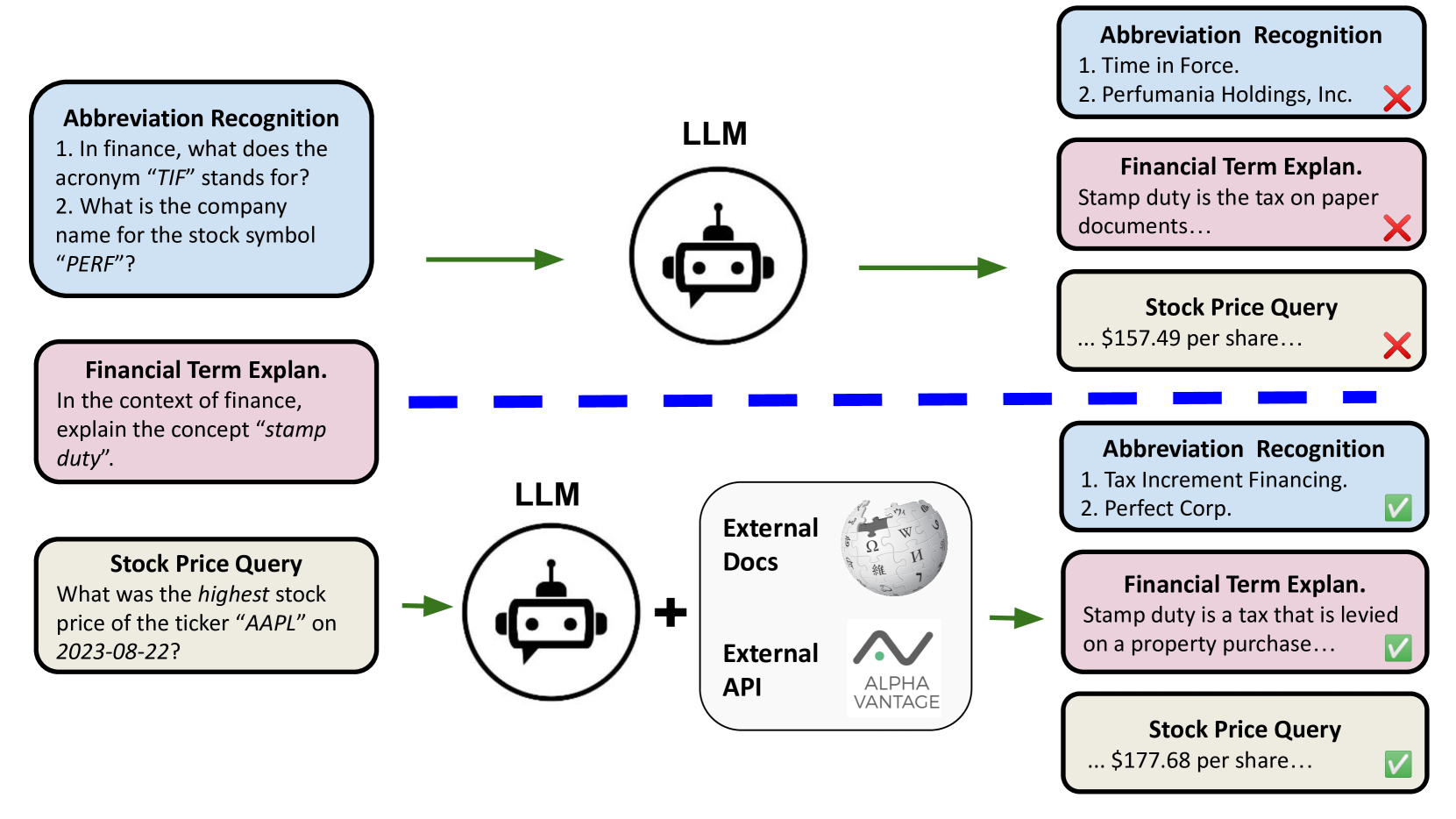
Overview of the empirical examination framework, showing input questions, the hallucination problem (e.g., GPT-4 confusing 'TIF' definitions), and the mitigation methods (RAG, Tools).
Evaluation Highlights
- Prompt-based tool learning achieves 100% accuracy on stock price queries for Llama-2 models with just one training example, compared to 0% accuracy without tools
- RAG significantly improves FactScore on financial term explanations, raising Llama-2-7B-chat performance from 38.3% to 62.5%
- GPT-4 achieves 90.4% accuracy on stock symbol recognition but still hallucinates outdated information (e.g., delisted stocks)
Breakthrough Assessment
7/10
Provides a necessary empirical reality check for FinLLMs, highlighting that standard fine-tuning isn't a silver bullet and establishing strong baselines for tool-augmented mitigation.