📝 Paper Summary
Sequential Recommendation
Generative Recommendation
GLoSS combines efficient quantized LLMs for query generation with dense semantic retrieval to recommend items based on textual meaning rather than just ID matching.
Core Problem
Traditional ID-based recommenders struggle with cold-start items and lack generalization, while prior generative approaches often rely on outdated models or lexical matching (BM25) that misses semantic context.
Why it matters:
- ID-based methods require retraining for new items and cannot leverage rich metadata descriptions
- Existing generative methods like GPT4Rec use lexical matching (BM25), failing to capture the semantic intent of generated queries
- Full fine-tuning of LLMs for recommendation is computationally expensive and resource-intensive
Concrete Example:
A user buys a 'Cosplay Hair Wig'. A lexical system might only find items with exact word overlaps like 'Hair Wig'. GLoSS generates a descriptive query for the next likely purchase (e.g., 'Spiral Curly Cosplay Wig') and uses semantic search to find conceptually similar items even if the exact words differ.
Key Novelty
Generative Low-rank language model with Semantic Search (GLoSS)
- Replaces the lexical matching (BM25) used in prior works like GPT4Rec with dense semantic search, allowing retrieval of items based on meaning rather than just keyword overlap
- Uses modern LLaMA-3 models fine-tuned via 4-bit QLoRA, enabling high-quality query generation on consumer-grade hardware compared to older, compute-heavy backbones like GPT-2 or T5
Architecture
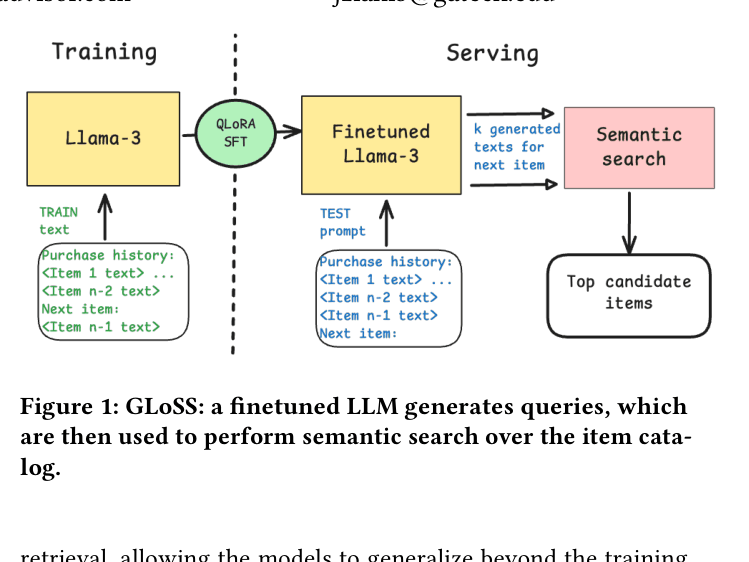
The GLoSS inference pipeline: from user history serialization to LLM query generation and dense item retrieval.
Evaluation Highlights
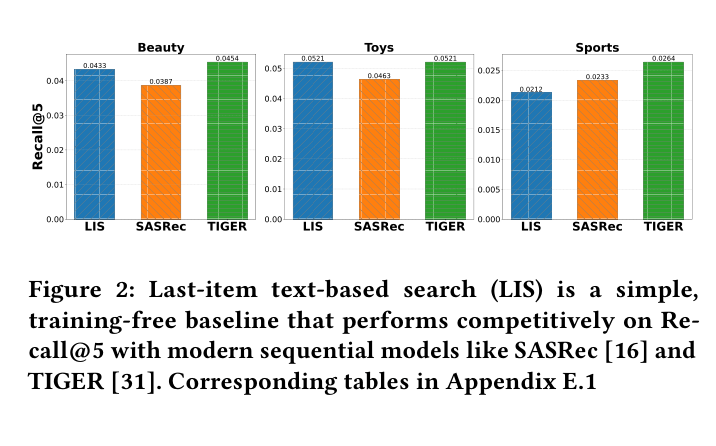
- +52.8% Recall@5 improvement on Amazon Toys compared to the best performing ID-based baseline (TIGER)
- +33.3% Recall@5 improvement on Amazon Beauty compared to ID-based baselines
- +29.5% Recall@5 improvement on Amazon Sports compared to E4SRec (LLM-based baseline)
Breakthrough Assessment
8/10
Significant double-digit gains over SOTA baselines by modernizing the generative retrieval pipeline with LLaMA-3 and dense search. Demonstrates high effectiveness for cold-start users.