📝 Paper Summary
Hallucination detection
Factual consistency evaluation
Meta-evaluation of LLM judges
FINAL is a new benchmark for evaluating LLMs on localizing factual hallucinations, using free-form natural language descriptions to capture complex errors that rigid formats like spans or atomic facts miss.
Core Problem
Existing fine-grained hallucination evaluation methods use rigid error representations (entities, spans, QA pairs) that cannot express all error types and often rely on complex, impractical pipelines.
Why it matters:
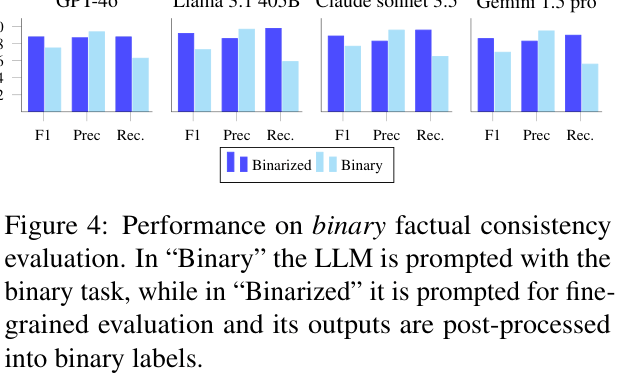
- Binary classification (consistent vs. inconsistent) overlooks severity and fails to pinpoint errors for correction
- Current fine-grained formats like atomic facts or spans are often vague or fail to capture nuanced errors (e.g., 'record number of sales' where sales occurred but no record was set)
- There is no established benchmark for meta-evaluating LLMs on the task of end-to-end hallucination localization
Concrete Example:
A summary claims 'Amazon made a record number of sales.' The source mentions 250,000 sales but never calls it a 'record.' Span highlighting is ambiguous (highlight 'record' or 'sales'?), and atomic facts might flag the whole sentence. The proposed method generates a description: 'The summary calls the sales a record, but the text says surpassing 250,000 units without mentioning a record.'
Key Novelty
The FINAL Benchmark & Natural Language Error Descriptions
- Replaces rigid error tags (spans, entities) with free-form natural language descriptions, allowing LLMs to express any type of factual inconsistency flexibly
- Introduces an LLM-based 'matching' protocol to evaluate these free-form descriptions against ground truth, overcoming the difficulty of comparing text outputs
- Constructs a high-quality dataset via expert human annotation and LLM-human collaboration to uncover missing errors in previous datasets (DeFacto)
Architecture
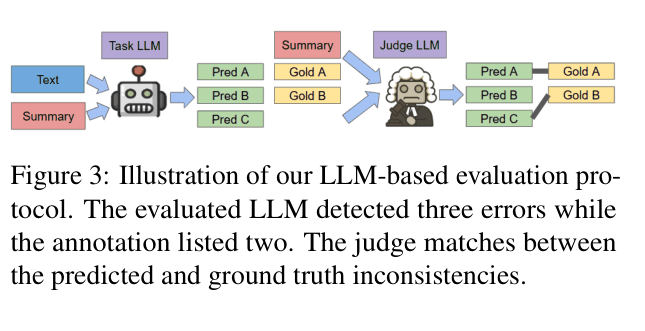
The LLM-based evaluation protocol (LLM-as-a-judge) used to score the performance of models on the benchmark.
Evaluation Highlights
- Current SOTA LLMs struggle on FINAL: The best performing model (GPT-4o) achieves only 0.67 F1 on end-to-end localization.
- Reasoning helps: Chain-of-Thought (CoT) prompting consistently outperforms zero-shot and few-shot approaches across all tested models (e.g., +0.12 F1 for Llama-3.1-405B).
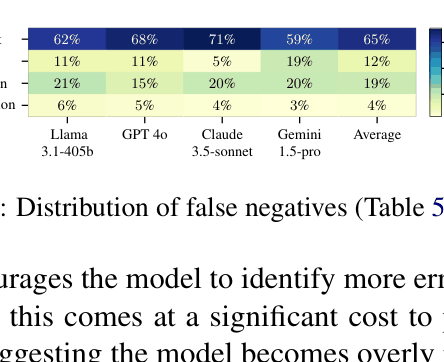
- Parametric knowledge interferes: Models frequently fail to detect 'Extrinsic Correct' errors (hallucinations that are factually true but not in the source) because the information aligns with their internal training data.
Breakthrough Assessment
8/10
Significantly advances meta-evaluation by abandoning rigid error formats for natural language descriptions, a more realistic approach for LLMs. The rigorous benchmark construction and analysis of 'Extrinsic Correct' failures provide valuable insights.