📝 Paper Summary
Hallucination evaluation
Prompt sensitivity
LLMs exhibit severe inconsistency (prompt multiplicity) where prompt variations alter answers despite stable overall accuracy, revealing that many hallucinations are random guesses rather than persistent misconceptions.
Core Problem
Current hallucination benchmarks focus only on correctness (accuracy) and overlook consistency, masking the difference between random guessing and persistent misinformation.
Why it matters:
- Random guessing (prompt-sensitive errors) erodes trust and causes confusion but can be managed with uncertainty estimation
- Persistent errors (prompt-agnostic errors) spread misinformation and require external fact-checking or data filtering
- Existing benchmarks treat both error types identically, leading to a severe misunderstanding of the true harms and appropriate mitigation strategies
Concrete Example:
On Med-HALT, Llama3-8B selects 'Tetracycline' (wrong) for one prompt but 'Ibuprofen' (wrong) or 'Amoxicilin' (wrong) when MCQ options are shuffled. Conversely, Llama3-8B-Instruct consistently selects 'Tetracycline'. Benchmarks score both as 'incorrect', missing that the first is random noise and the second is a dangerous, persistent medical error.
Key Novelty
Prompt Multiplicity Framework for Hallucinations
- Formalize consistency using 'prompt multiplicity'—the phenomenon where models with similar accuracy give conflicting predictions for individual questions based on prompt structure
- Decompose 'hallucinations' into 'randomness' (prompt-sensitive) and 'prompt-agnostic errors' (persistent), and 'factuality' into 'prompt-agnostic factuality' and 'prompt-sensitive correct guesses'
- Demonstrate that detection methods align with consistency rather than correctness, and that RAG introduces new inconsistency via retrieval sensitivity
Architecture
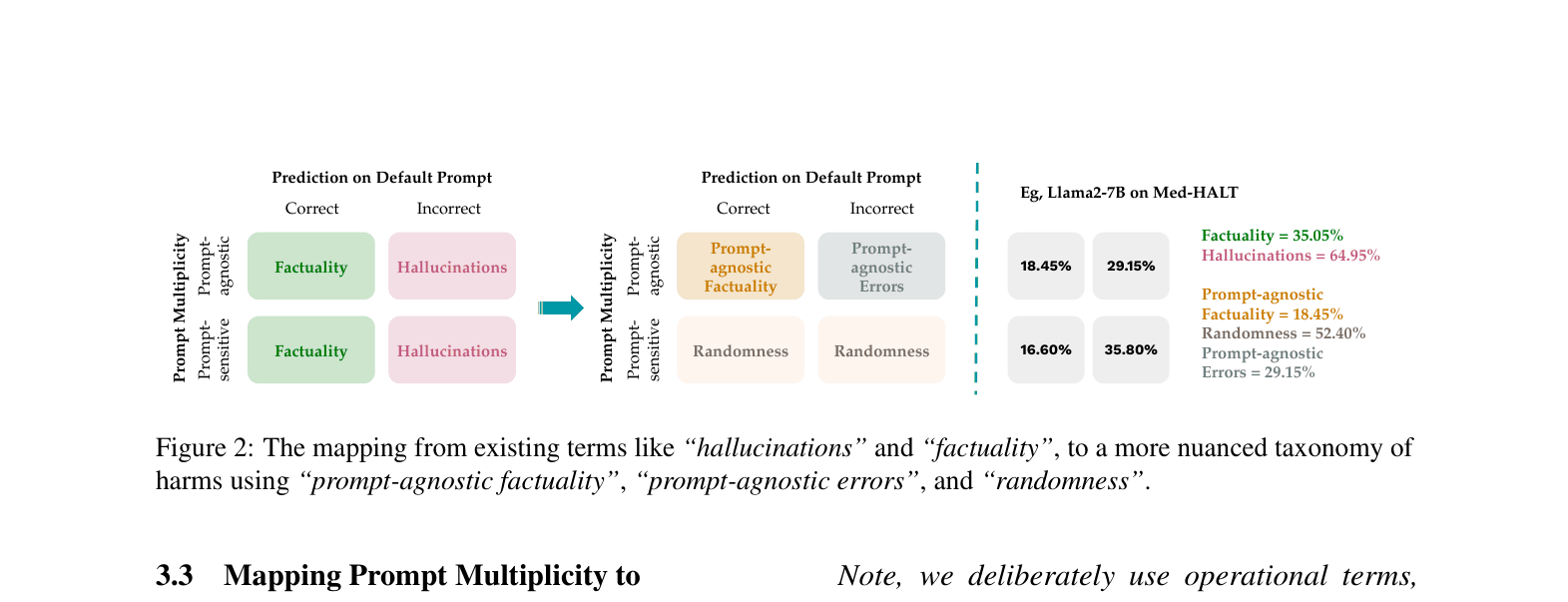
A taxonomy mapping traditional 'Factuality' and 'Hallucinations' to 'Prompt-agnostic Factuality', 'Randomness', and 'Prompt-agnostic Errors' based on prompt multiplicity.
Evaluation Highlights
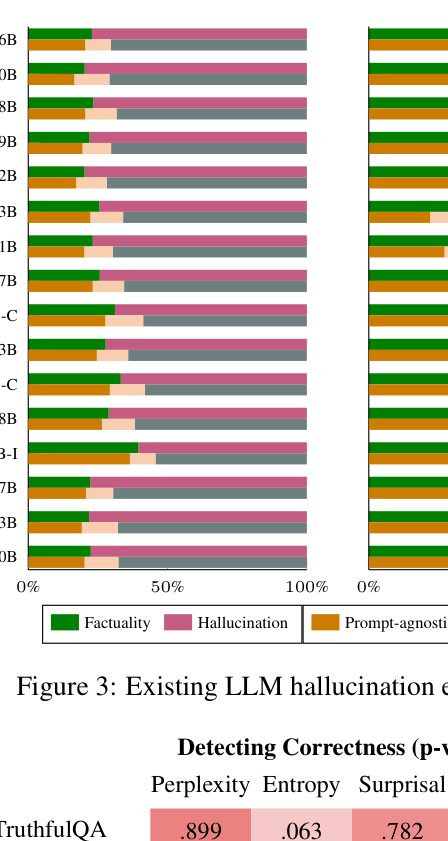
- Over 50% ambiguity (inconsistency) observed in benchmarks like Med-HALT for models like Llama2-13B-Chat, despite low accuracy variance (<0.5%)
- Detection methods (Perplexity, SelfCheck) show high statistical significance (p < .001) when distinguishing consistent vs. inconsistent answers, but fail to distinguish correct vs. incorrect answers (p > .05 for Perplexity on Wiki-FACTOR)
- RAG mitigation reduces overall errors but introduces high retrieval ambiguity: >90% of random errors in FEVER with RAG stem from the retriever selecting different documents for different prompts
Breakthrough Assessment
8/10
Significantly reframes the understanding of hallucinations by introducing consistency as a critical dimension. Exposes major flaws in current benchmarking and detection assumptions.