📝 Paper Summary
Agentic RAG pipeline
Compact Language Models (SLMs)
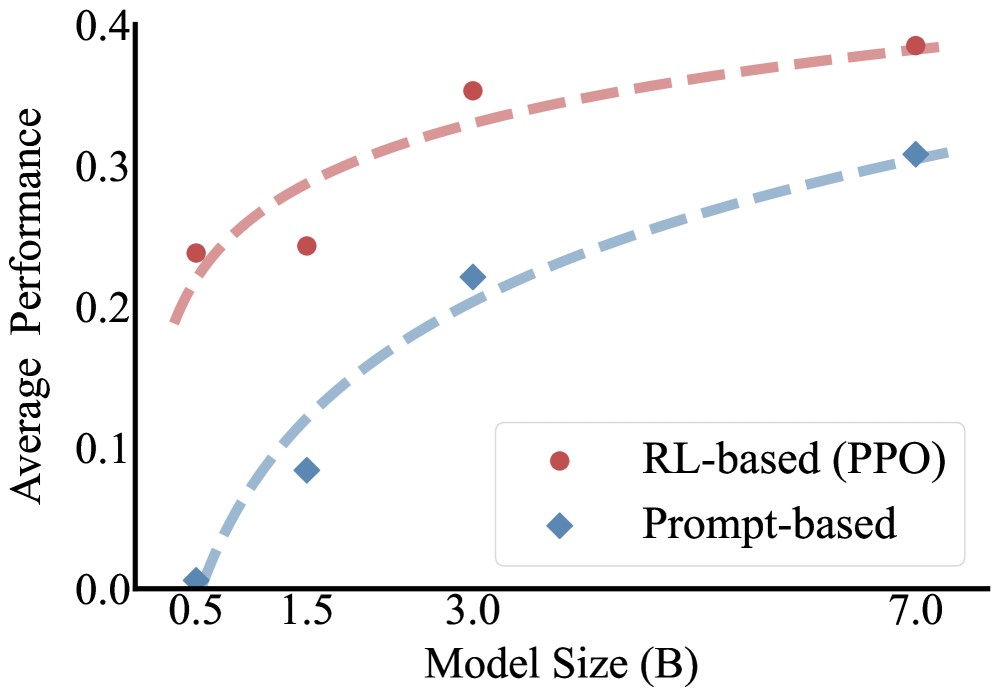
DGPO enables compact language models (0.5–1B parameters) to achieve sophisticated agentic RAG behaviors by combining cold-start distillation from a teacher with selective reinforcement learning that corrects only wrong reasoning paths.
Core Problem
Applying Reinforcement Learning (RL) to compact models for agentic RAG fails because their poor initial capabilities lead to sparse rewards and unstable training, while standard distillation suffers from exposure bias.
Why it matters:
- Agentic RAG systems currently rely on massive LLMs, making them inaccessible for resource-constrained environments.
- Smaller models (0.5-1B) struggle with the 'cold-start' problem in RL; they rarely generate correct search trajectories on their own to learn from.
- Standard distillation methods fail to transfer the complex decision-making process (when to search vs. answer) needed for autonomous agents.
Concrete Example:
When asked a complex multi-hop question like 'Whose album was Red?', a naive compact model might guess directly or search literally for keywords. A larger teacher model knows to rewrite the query to 'Red album artist'. Without guidance, the compact model rarely discovers this strategy on its own, leading to zero reward and no learning.
Key Novelty
Distillation-Guided Policy Optimization (DGPO)
- Initializes the student via cold-start distillation on teacher-generated correct trajectories to establish a baseline capability.
- During RL, uses a selective 'mimic if wrong, reward if right' mechanism: the student is rewarded for correct answers but penalized with KL divergence toward the teacher only when it fails.
- Introduces Agentic RAG Capabilities (ARC), a fine-grained evaluation metric decomposing performance into thinking, query rewriting, and source referencing components.
Architecture
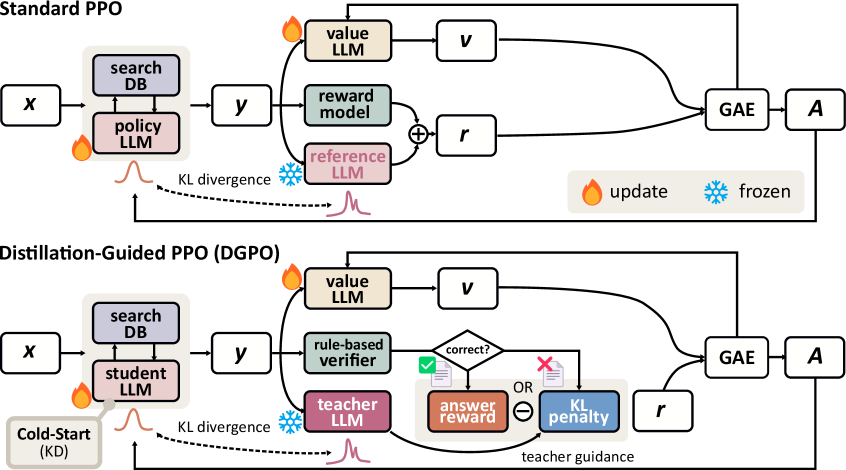
The DGPO training framework illustrating the two-phase process: Cold-Start Initialization and Distillation-Guided RL.
Evaluation Highlights
- DGPO with a 0.5B student outperforms the 3B teacher model on NQ (48.1 vs 47.9), PopQA (45.3 vs 44.2), and HotpotQA (44.6 vs 43.5) datasets.
- Achieves highest average Exact Match score (40.0) across 7 QA datasets compared to PPO (36.0), KD (38.8), and GKD (31.1) using Qwen2.5-0.5B.
- Generalizes across model families: Llama-3-1B student trained via DGPO outperforms standard PPO by +4.8 points on average (37.3 vs 32.5).
Breakthrough Assessment
8/10
Demonstrates that extremely small models (0.5B) can outperform significantly larger teachers in agentic tasks, challenging the assumption that agentic RAG requires massive parameters.