📝 Paper Summary
Multimodal Large Language Models (Omni-LLMs)
Hallucination Mitigation
Direct Preference Optimization (DPO)
MoD-DPO reduces cross-modal hallucinations in omni-modal LLMs by explicitly decoupling modalities during preference optimization, enforcing invariance to irrelevant modality corruption and sensitivity to relevant modality corruption.
Core Problem
Omni-modal LLMs suffer from cross-modal hallucinations (e.g., hearing imaginary sounds from visual cues) due to spurious inter-modality correlations and over-reliance on strong language priors.
Why it matters:
- Models hallucinate non-existent events (e.g., 'hearing' a dog because one is visible) when audio/video evidence is weak or asynchronous.
- Existing multimodal DPO methods do not explicitly decouple modality pathways, allowing models to retain latent language-only shortcuts.
- Reliable audiovisual understanding is critical for agents that must 'see and listen' accurately before reasoning.
Concrete Example:
When an omni-LLM sees a video of a dog but the audio is silent, it might hallucinate a 'barking' sound solely because dogs usually bark (spurious correlation/language prior). MoD-DPO prevents this by ensuring the model's audio prediction doesn't change if the video is corrupted (invariance).
Key Novelty
Modality-Decoupled Direct Preference Optimization (MoD-DPO)
- Adds regularization terms to the DPO objective that force the model's output to stay stable when the *irrelevant* modality is corrupted (invariance).
- Forces the model's output to shift significantly when the *relevant* modality is corrupted (sensitivity), ensuring true grounding.
- Incorporates a Language Prior Debiasing (LPD) penalty that specifically reduces rewards for responses that could be generated by text priors alone.
Architecture
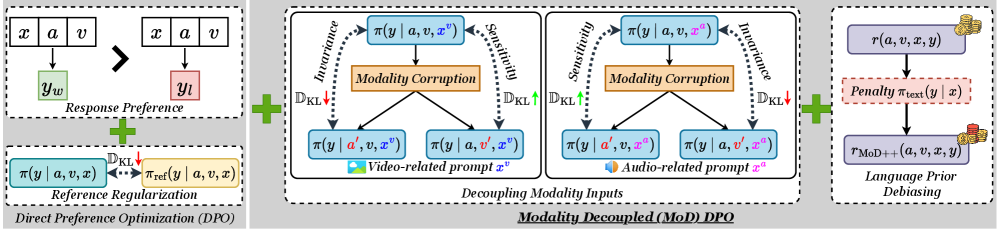
Comparison of Vanilla DPO vs. MoD-DPO objectives. It visualizes how MoD-DPO splits the input into relevant/irrelevant modalities and applies specific regularization.
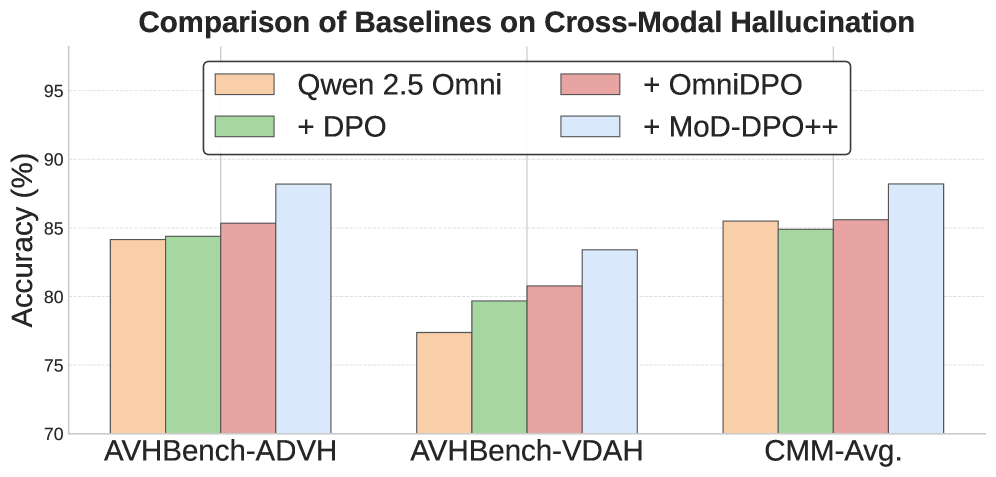
Evaluation Highlights
- +27% accuracy improvement on audiovisual matching tasks in AVHBench compared to the reference model (Qwen 2.5 Omni).
- Outperforms baselines (Vanilla DPO, OmniDPO, V-DPO) on CMM benchmark for both perception accuracy and hallucination resistance.
- Achieves these gains while maintaining general audiovisual capabilities on benchmarks like MVBench and MMAU.
Breakthrough Assessment
8/10
Strong methodological contribution by deriving a closed-form solution for modality-decoupled DPO. Significant empirical gains (+27%) on specific hallucination tasks address a critical failure mode of multimodal models.