📝 Paper Summary
3D Vision-Language Modeling
Embodied AI
Instruction Tuning
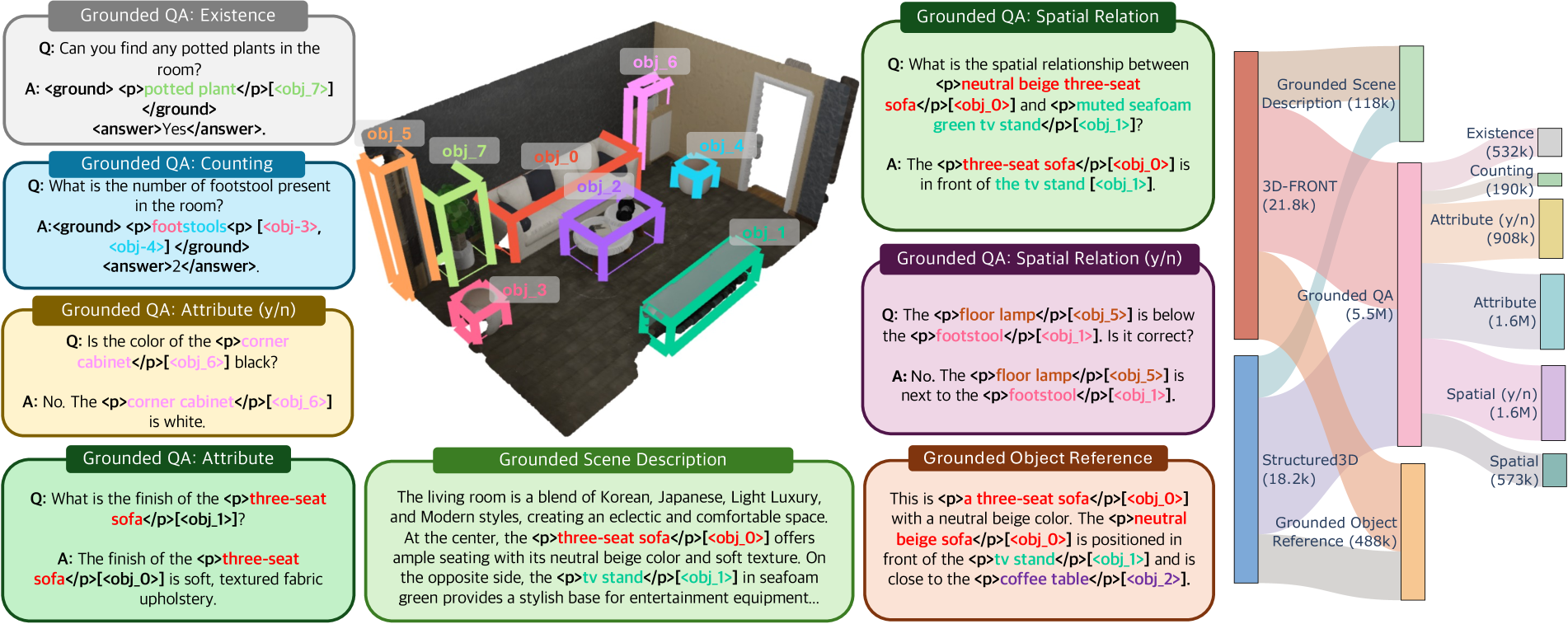
3D-GRAND introduces a massive dataset of 6.2 million densely-grounded 3D-text pairs and a new hallucination benchmark, demonstrating that large-scale synthetic data scaling significantly improves 3D-LLM grounding and reduces hallucination.
Core Problem
Existing 3D-LLM datasets are small-scale, lack dense grounding (associating every noun phrase with 3D objects), and current benchmarks fail to systematically evaluate object hallucination in 3D models.
Why it matters:
- Without dense grounding, robots and agents cannot reliably connect abstract language instructions to physical objects, leading to navigation and manipulation failures.
- Scarcity of 3D-text pairs limits 3D-LLMs compared to their 2D counterparts, which benefit from billion-scale datasets.
- Hallucination in 3D-LLMs is largely unexplored and unmeasured, undermining trust in embodied agents.
Concrete Example:
In SceneVerse (prior work), a sentence like 'This is a big cotton sofa between the window and the table' is grounded only to the sofa. 3D-GRAND grounds 'sofa', 'window', and 'table' to specific 3D objects, preventing ambiguity.
Key Novelty
Scaling Densely-Grounded Synthetic 3D Data
- Leverage synthetic 3D scene generation pipelines (3D-FRONT, Structured3D) to create large-scale environments without expensive real-world scanning.
- Use a pipeline involving 2D-LLMs (GPT-4V) and scene graphs to automatically generate 6.2 million instruction-following pairs where every noun phrase is linked to a specific 3D object ID.
- Introduce a polling-based evaluation protocol (3D-POPE) specifically designed to probe whether 3D-LLMs hallucinate non-existent objects.
Architecture
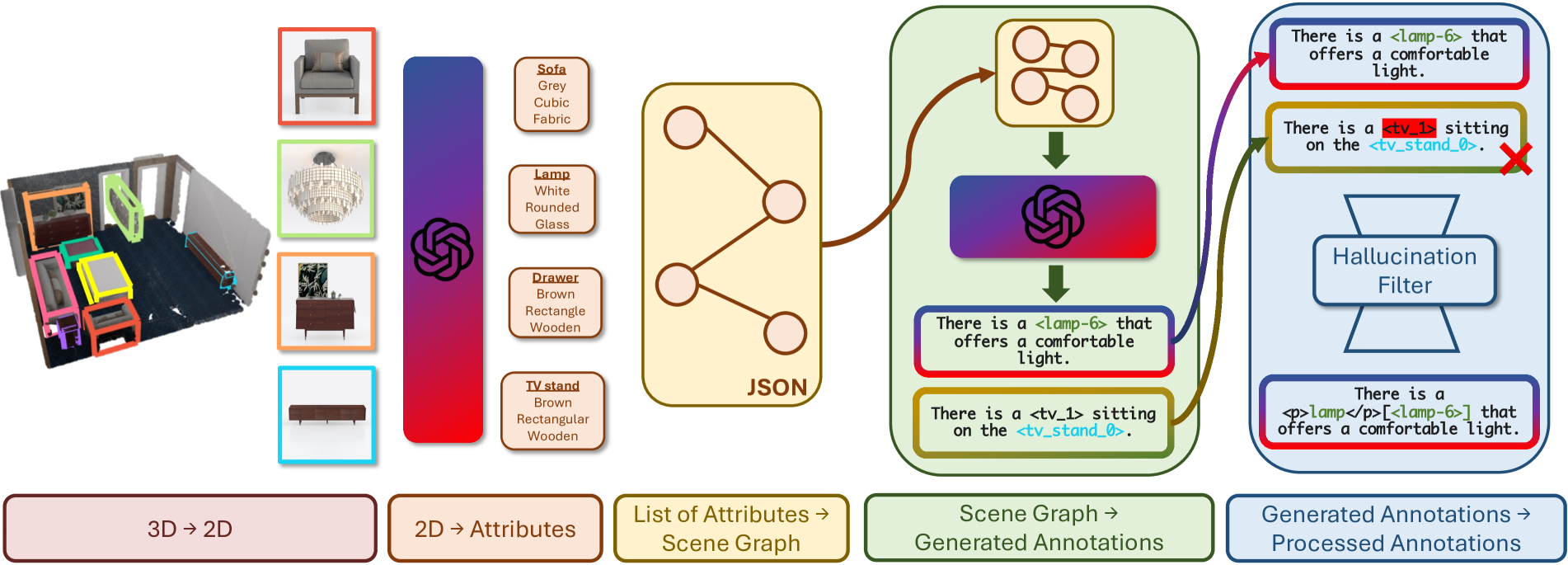
The data generation pipeline for 3D-GRAND.
Evaluation Highlights
- Outperforms the previous state-of-the-art 3D-LLM by +7.7% on Accuracy@0.25IoU on the ScanRefer benchmark, despite training only on synthetic data (zero-shot transfer to real ScanNet scenes).
- Achieves 93.34% Precision on the 3D-POPE hallucination benchmark (Random sampling), significantly reducing object hallucination compared to baselines.
- Data scaling analysis shows consistent performance improvements when increasing training data from 10% to 100% of the dataset.
Breakthrough Assessment
9/10
The dataset scale (6.2M densely grounded pairs) is a massive leap over prior work. The demonstration of effective sim-to-real transfer for 3D grounding is highly significant for the field.