📝 Paper Summary
Hallucination suppression
Benchmark datasets
Metrics and evaluation
Lynx is an open-source hallucination detection model trained on a new, semantically perturbed benchmark (HaluBench) that outperforms closed-source models like GPT-4o in identifying unfaithful RAG responses.
Core Problem
RAG systems frequently produce hallucinations where answers are inconsistent with retrieved contexts, and existing detection methods (like closed-source LLM judges) lack transparency, struggle with nuanced reasoning, or fail in specialized domains.
Why it matters:
- Closed-source LLM judges (GPT-4o) lack transparency and are costly for large-scale evaluation
- Existing open-source judges lag significantly behind closed-source performance, especially in finance and medicine
- Current benchmarks lack diverse, real-world domain coverage and sufficiently difficult test cases requiring nuanced reasoning
Concrete Example:
In a RAG scenario, if a document states 'Revenue grew 5%', an LLM might answer 'Revenue grew significantly'. While directionally similar, this might be considered a hallucination in strict financial contexts. GPT-4o often fails to catch these subtle inconsistencies where the answer is correct in world knowledge but not supported by the specific retrieved text.
Key Novelty
Lynx (Open-Source Hallucination Judge) & HaluBench (Perturbation-Based Benchmark)
- Trains a dedicated judge model (Lynx) using reasoning traces distilled from GPT-4o to detect intrinsic hallucinations (faithfulness errors) in RAG outputs
- Constructs a challenging benchmark (HaluBench) by using an LLM to generate 'semantic perturbations'—subtle changes to ground-truth answers that make them unfaithful to the context, creating hard-to-detect negative examples
Architecture
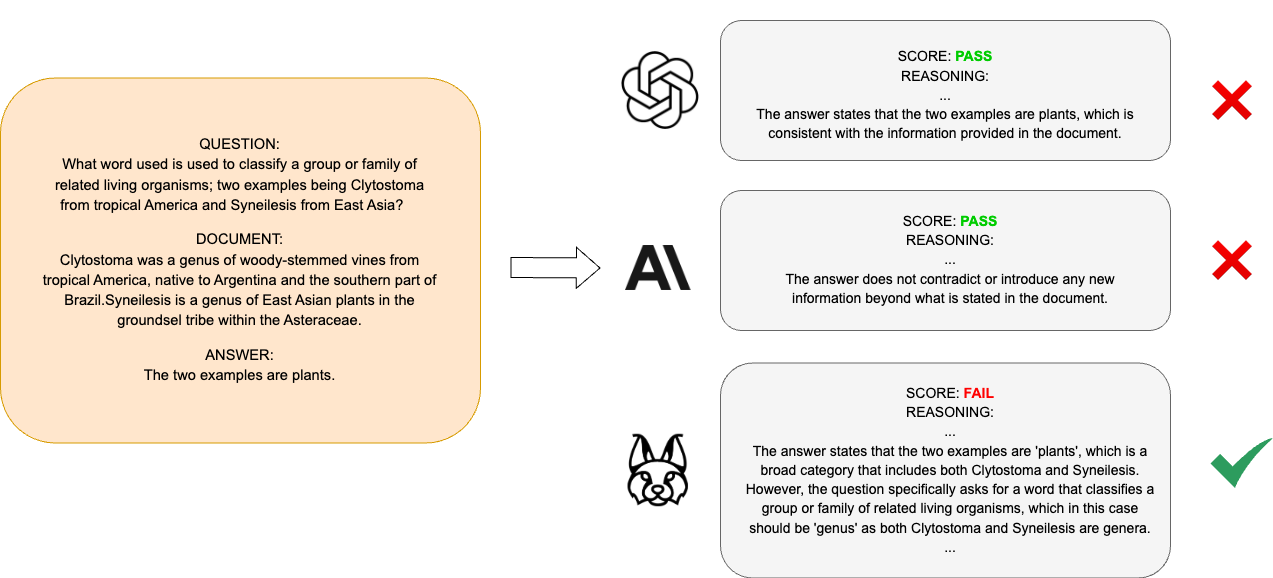
Conceptual workflow of the evaluation task where a model assesses a Context-Question-Answer triplet.
Evaluation Highlights
- Lynx-70B outperforms GPT-4o on HaluBench, achieving higher accuracy in detecting hallucinations across diverse domains
- Lynx-8B produces high-quality evaluations at a fraction of the size/cost, outperforming other open-source judges
- HaluBench comprises 15k samples across finance, medicine, and general domains, validating model performance on real-world scenarios
Breakthrough Assessment
8/10
Significantly closes the gap between open and closed-source models for hallucination detection. The perturbation methodology for creating hard negatives is a practical contribution to evaluation robustness.