📝 Paper Summary
Visual Hallucination Detection
Multi-Modal Agentic Verification
Pelican detects and corrects visual hallucinations by decomposing claims into sub-questions, generating Python code to answer them via external tools, and sharing computation context between steps.
Core Problem
Large Vision Language Models (LVLMs) suffer from hallucinations due to limited training data, lack of precise grounding, and over-reliance on language priors.
Why it matters:
- Hallucinations limit the trustworthiness and real-world applicability of LVLMs in visual instruction following tasks
- Prior verification methods like Woodpecker lack precise grounding for specific object instances and struggle with contextual reasoning around multiple objects
- Existing detectors often fail to identify inconsistencies in reasoning or adaptive corrections during the verification process
Concrete Example:
If a model claims 'The disposable coffee cups are upside down on the nightstand', a standard LVLM might hallucinate the cup's orientation or location. Pelican parses this into {cups, nightstand}, verifies their existence via detection, and generates code to check the specific relation 'upside down' rather than guessing.
Key Novelty
Pelican (Program-of-Thought for Claim Verification)
- Decomposes visual claims into a chain of (predicate, question) pairs that form a computational graph
- Uses Program-of-Thought prompting to generate Python code that answers sub-questions by composing external tools (VQA, detectors) with native Python operators
- Introduces intermediate variables to precisely reference specific object instances and shares computation results between steps to enable adaptive corrections
Architecture
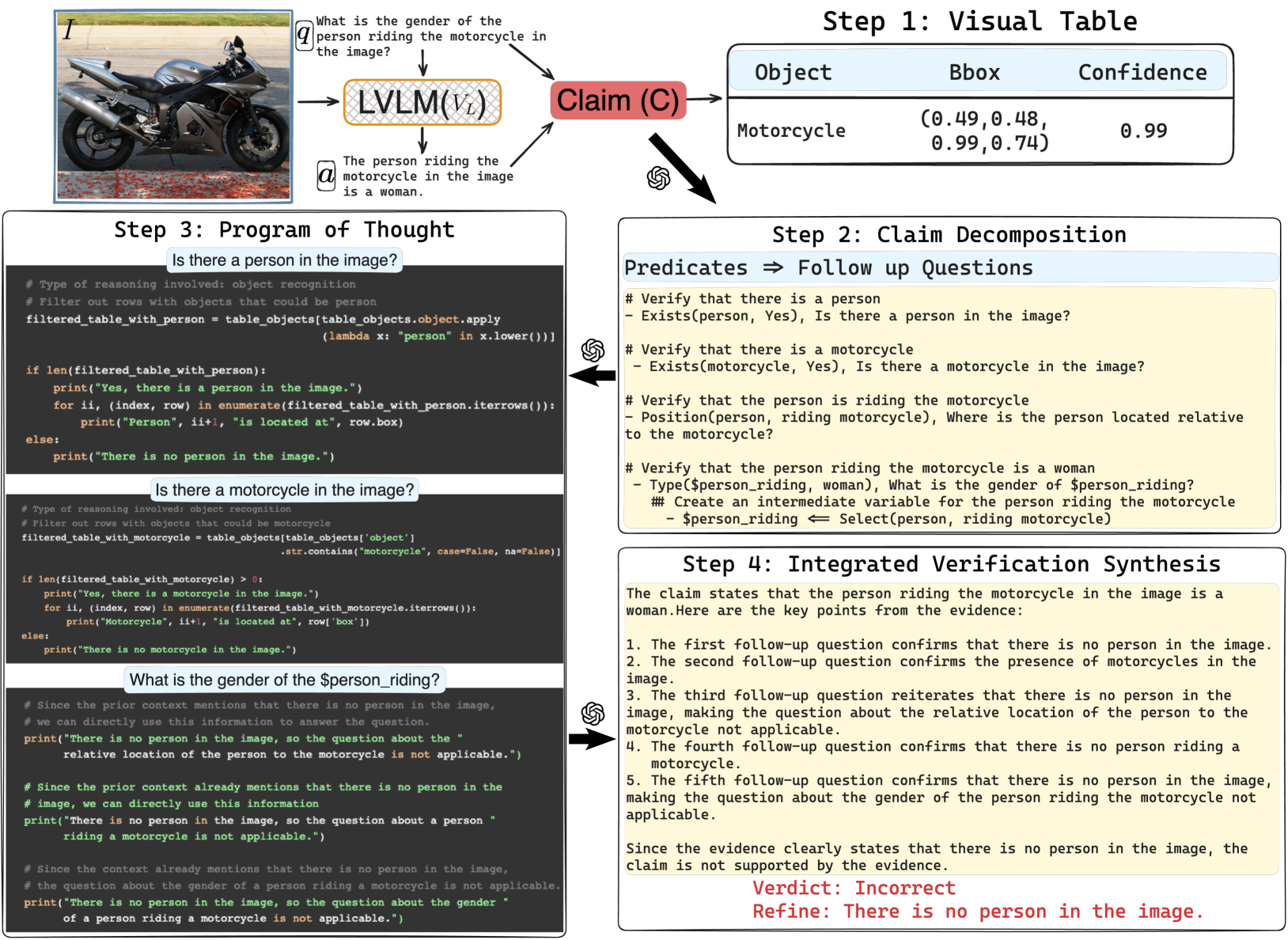
The Pelican pipeline: Claim Decomposition -> Program of Thought Verification -> Reasoning & Correction.
Evaluation Highlights
- Reduces hallucination rate by ~8%-32% across various baseline LVLMs on MMHal-Bench
- Achieves a 27% drop in hallucinations compared to the best previous mitigation approach (Woodpecker) on MMHal-Bench
- Demonstrates consistent improvements on GAVIE and MME benchmarks, improving visual understanding accuracy
Breakthrough Assessment
7/10
Strong methodological contribution by integrating Program-of-Thought with claim verification. Significant empirical gains over previous SOTA (Woodpecker). However, reliance on off-the-shelf tools limits it to the performance of those underlying detectors.