📝 Paper Summary
Theoretical limits of LLMs
Hallucination impossibility results
Using formal learning theory, this paper proves that it is mathematically impossible for any computable Large Language Model (LLM) to completely eliminate hallucination, regardless of model size or training data.
Core Problem
Current research on hallucination is largely empirical and cannot answer the fundamental question of whether hallucination can ever be completely eliminated.
Why it matters:
- Safety-critical deployment of LLMs requires knowing if errors can be reduced to zero or if they are an inherent flaw
- Without formal proofs, researchers may waste resources chasing an unattainable goal of 'perfect' factuality
- Existing definitions of hallucination are often ambiguous due to the complexity of real-world semantics, making precise theoretical analysis difficult
Concrete Example:
Consider a 'formal world' where the ground truth is a specific computable function. The paper proves there will always exist an input string for which a trained LLM fails to output the correct value defined by that function, even with infinite training time.
Key Novelty
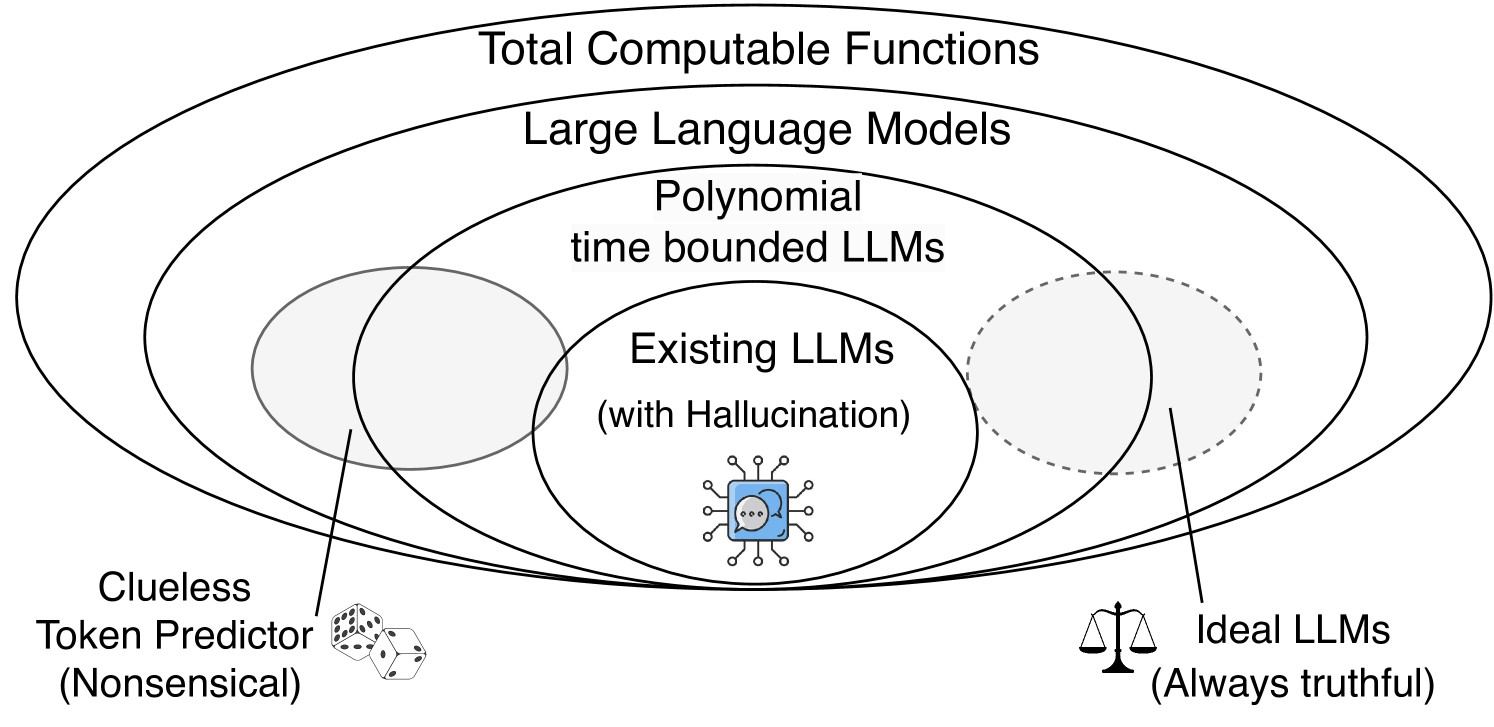
Hallucination Inevitability Theorem
- Formalizes 'hallucination' as inconsistency between an LLM and a computable ground truth function within a rigorous mathematical framework
- Applies results from learning theory (specifically regarding the identification of functions) to show that the class of all computable functions cannot be learned by any single computable learner (the LLM)
- Demonstrates that since this impossibility holds in a simplified 'formal world', it necessarily holds in the more complex real world
Architecture
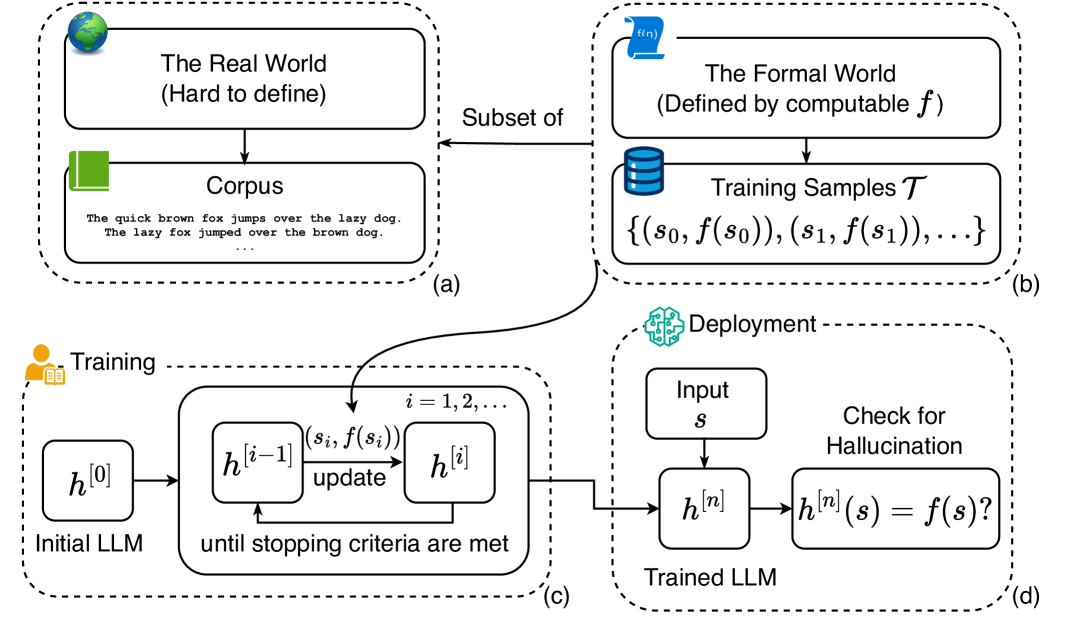
Conceptual framework of the formal world, relating ground truth functions, training samples, and LLM states.
Evaluation Highlights
- Proves theoretically that for any computable LLM, there exists a ground truth function it cannot learn without error (hallucination)
- Identifies specific tasks prone to hallucination, such as those equivalent to the 'Halting Problem'
- Empirically validates that real-world LLMs fail on undecidable problems, with accuracy dropping as problem complexity increases (qualitative result)
Breakthrough Assessment
9/10
Establishes a fundamental theoretical upper bound on LLM capabilities, similar to the Halting Problem in computer science. It shifts the discourse from 'how to fix hallucination' to 'how to manage inevitable hallucination'.