📝 Paper Summary
Hallucination detection
Hallucination mitigation
Automated evaluation
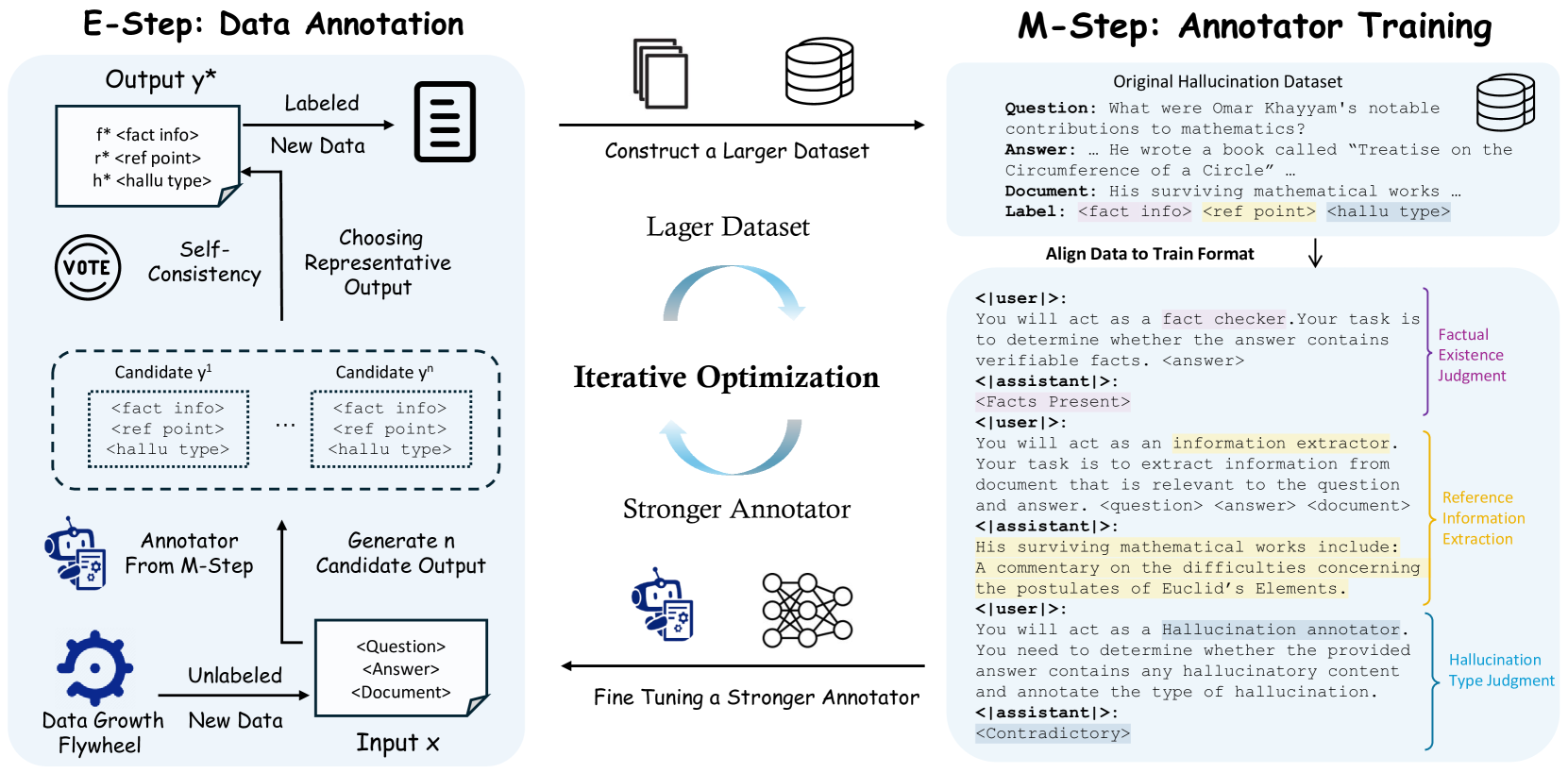
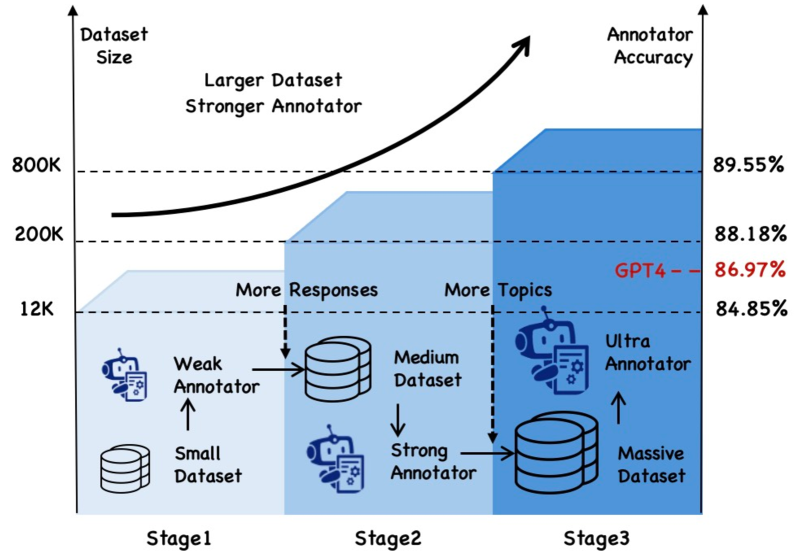
ANAH is an iterative self-training framework that progressively scales up hallucination annotation datasets and improves annotator accuracy by alternating between annotating new data and retraining the annotator model.
Core Problem
Existing hallucination datasets are small and domain-limited due to high human annotation costs, while current automatic annotators (including GPT-4) lack the reliability needed for scalable oversight.
Why it matters:
- Manual fine-grained annotation requires intensive labor to verify facts against long documents, making it prohibitively expensive to scale
- Unreliable automatic annotators produce inaccurate results, hindering the ability to detect and mitigate hallucinations in real-world LLM applications
- Limited dataset diversity prevents models from generalizing to hallucinations across different domains and response styles
Concrete Example:
When asking an LLM about a specific event, it might generate a plausible but incorrect detail. A standard annotator might miss this or hallucinate its own judgment. ANAH mitigates this by breaking the judgment into factual existence, reference extraction, and type determination, then self-training on these rigorous steps.
Key Novelty
Iterative Self-Training via Expectation Maximization
- Treats the dataset scaling process like an Expectation Maximization (EM) algorithm: the 'Expectation' step estimates ground-truth annotations on new data using the current best model, and the 'Maximization' step trains a better model on this larger dataset
- Decomposes the annotation task into three distinct cognitive phases (Factuality Check → Reference Extraction → Hallucination Type) to mirror human verification processes
- Uses a self-consistency strategy during the annotation phase to ensure robust labels for the next round of training, filtering out noise from the model's predictions
Architecture
The iterative self-training framework showing the EM cycle (E-step: Annotation Pipeline, M-step: Training) and the three stages of data scaling.
Evaluation Highlights
- +8.2% accuracy improvement over GPT-4 on the HaluEval benchmark (81.54% vs 73.34%) using the 7B parameter ANAH-v2 model
- +12% improvement in Natural Language Inference (NLI) metric (from 25% to 37%) on HaluEval when using the annotator to rerank LLM generations
- Achieves state-of-the-art zero-shot results on HalluQA (94.44%) and the in-domain ANAH benchmark (89.24%)
Breakthrough Assessment
8/10
Significantly outperforms GPT-4 with a much smaller 7B model for hallucination detection. The iterative self-training framework offers a scalable path for dataset creation without heavy human labeling.