📝 Paper Summary
Memory recall
Hallucination suppression
By simply scaling the length of memory readout vectors in the Larimar architecture, hallucination can be significantly reduced without retraining the model.
Core Problem
Large Language Models often hallucinate facts during generation, and existing mitigation techniques like model editing or context-grounding are computationally expensive or require retraining.
Why it matters:
- Hallucinations undermine trust in LLMs for factual tasks like biography generation.
- Current solutions like GRACE require expensive iterative backpropagation to update model weights or adapters.
- There is a need for lightweight, training-free methods to enforce factual consistency using internal model representations.
Concrete Example:
When generating a biography for 'Sir John Russell Reynolds', a standard model hallucinates he was 'born in London' (incorrect). The proposed method scales the memory readout vector, forcing the decoder to align with the correct fact ('born in Romsey') stored in memory, producing a factual output.
Key Novelty
Geometry-Aware Vector Scaling in Memory Readouts
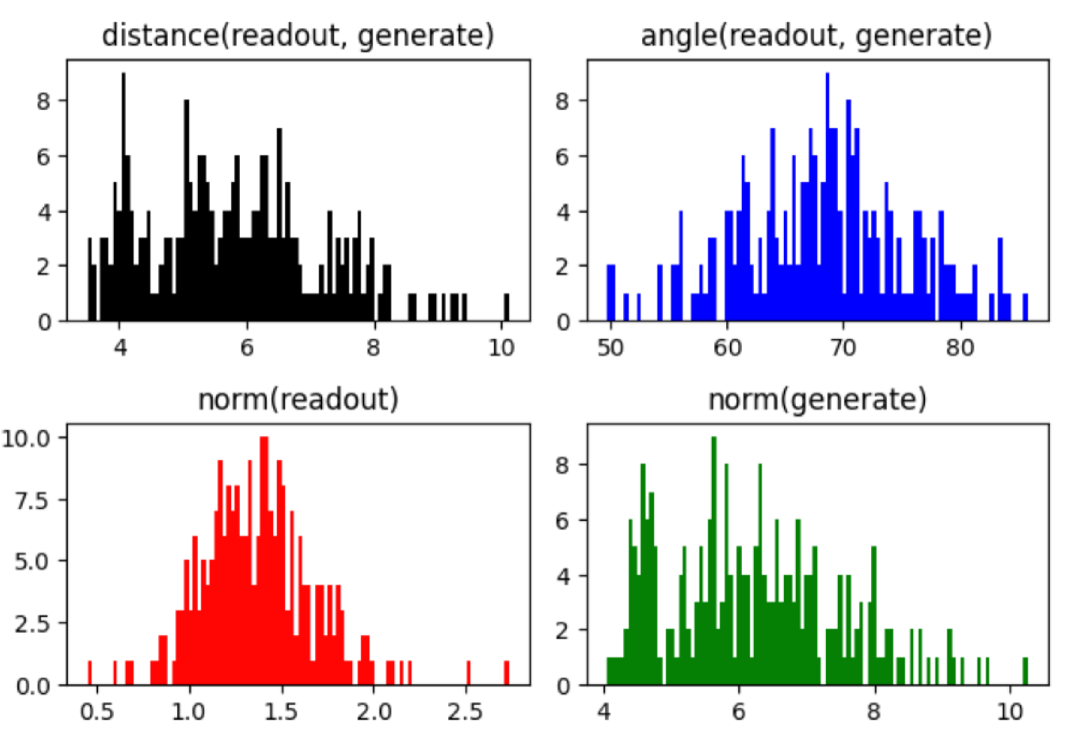
- Observes that the Larimar decoder geometrically distorts memory readout vectors, shrinking them and altering their angles relative to the original 'write' vectors.
- Proposes manually scaling up the magnitude (length) of the readout vector by a fixed factor before feeding it to the decoder.
- This simple geometric operation aligns the readout closer to the original memory encoding, effectively constraining the decoder to stick to the stored facts without any training.
Architecture
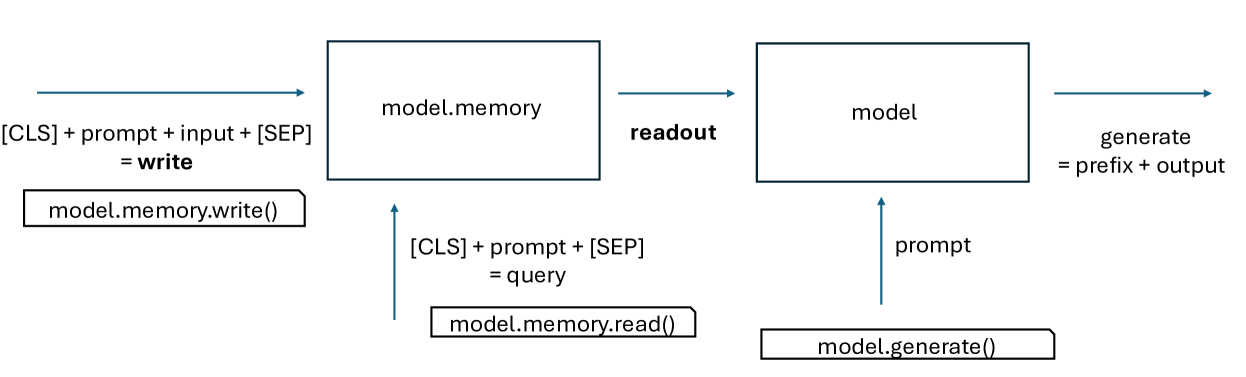
The Larimar pipeline for hallucination mitigation.
Evaluation Highlights
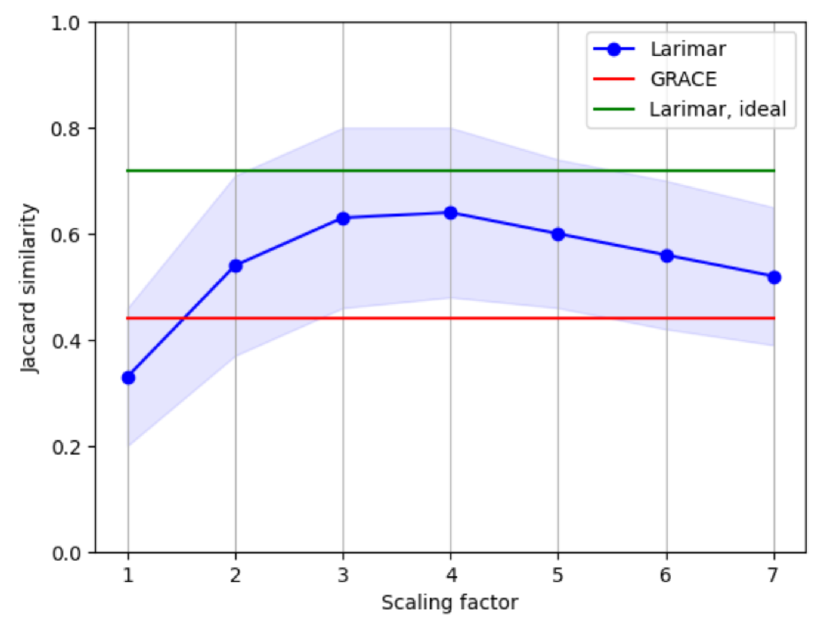
- Achieves 0.72 RougeL score on WikiBio hallucination benchmark, a 46.9% improvement over the GRACE baseline (0.49).
- Jaccard similarity improves from 0.33 (base Larimar) to ~0.65-0.70 with scaling factor s=4, significantly outperforming GRACE (0.44).
- Synthesis speed is 1-2 orders of magnitude faster than GRACE (3.1s vs 162.5s per entry) due to avoiding iterative backpropagation.
Breakthrough Assessment
7/10
Simple, highly effective training-free intervention with massive speed gains over SOTA model editing. However, heavily reliant on the specific Larimar architecture.