📝 Paper Summary
Multi-agent collaboration
Uncertainty quantification in LLMs
The paper improves multi-agent reasoning by integrating a third-party LLM to estimate agent confidence and dynamically adjusting attention weights based on uncertainty, reducing hallucinations in complex tasks.
Core Problem
Standard multi-agent debate systems often use identical models for all agents, leading to monolithic viewpoints and 'hallucination consensus' where agents agree on wrong answers due to restricted knowledge scopes.
Why it matters:
- Homogeneous multi-agent systems lack external feedback, limiting the depth and breadth of debate needed for complex reasoning
- Without distinct viewpoints or confidence calibration, agents may reinforce each other's errors rather than correcting them
- Current methods often treat all agent contributions equally, failing to prioritize more confident or reliable reasoning paths
Concrete Example:
In an arithmetic problem like '3+27*3+7', three identical agents might incorrectly agree on '97' due to shared biases. The proposed method introduces an external agent (ERNIE) to evaluate confidence; if ERNIE signals low confidence in the group's consensus, the system lowers attention to those answers, preventing the error propagation.
Key Novelty
Uncertainty-Driven Third-Party Integration
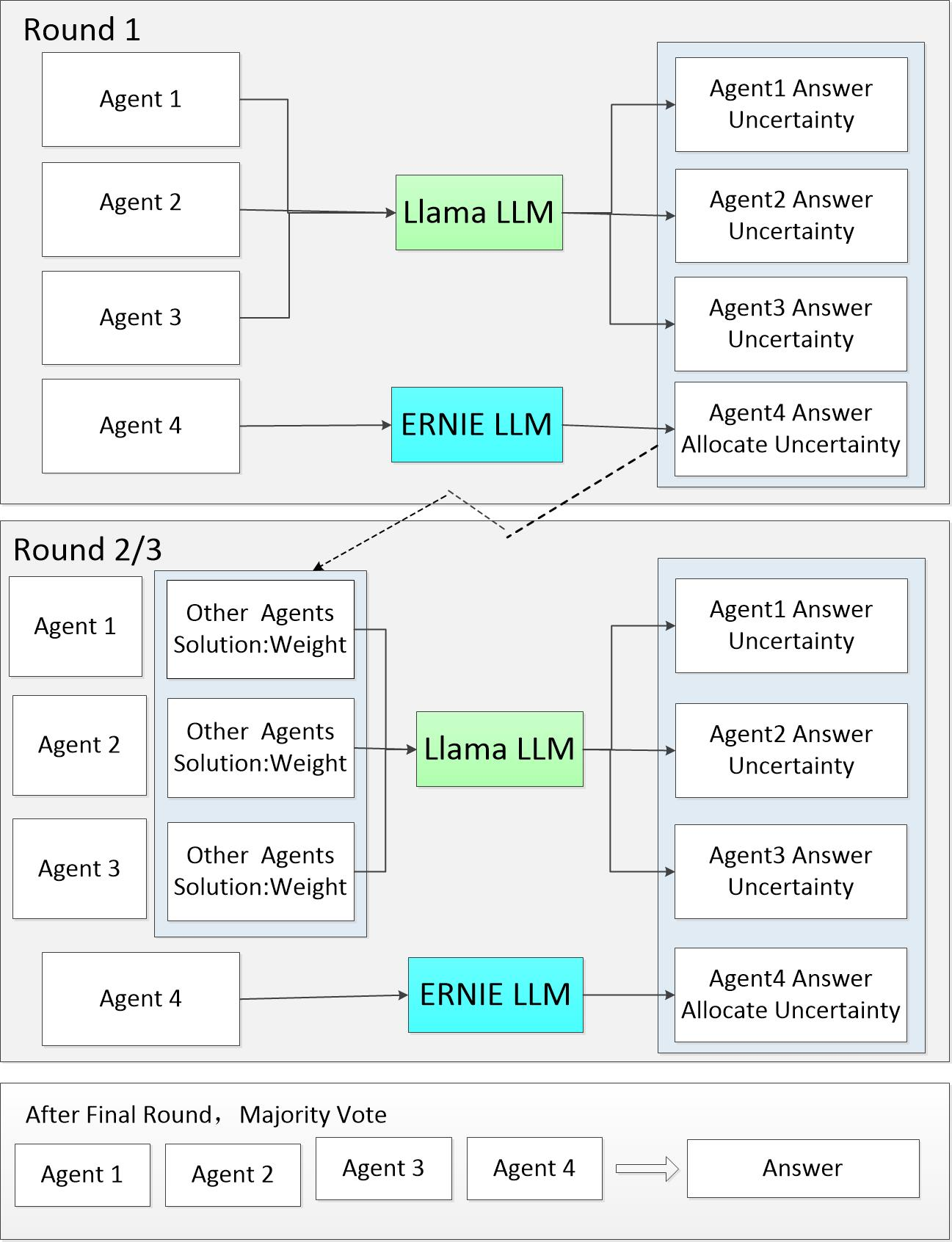
- Introduces a heterogeneous 'third-party' agent (ERNIE) into a homogeneous multi-agent group (Llama) to break monolithic consensus
- Calculates a confidence score for each agent's response based on logits and consistency
- Dynamically scales the attention weights of the primary model (Llama) to focus more on agents with higher confidence scores during the debate process
Architecture
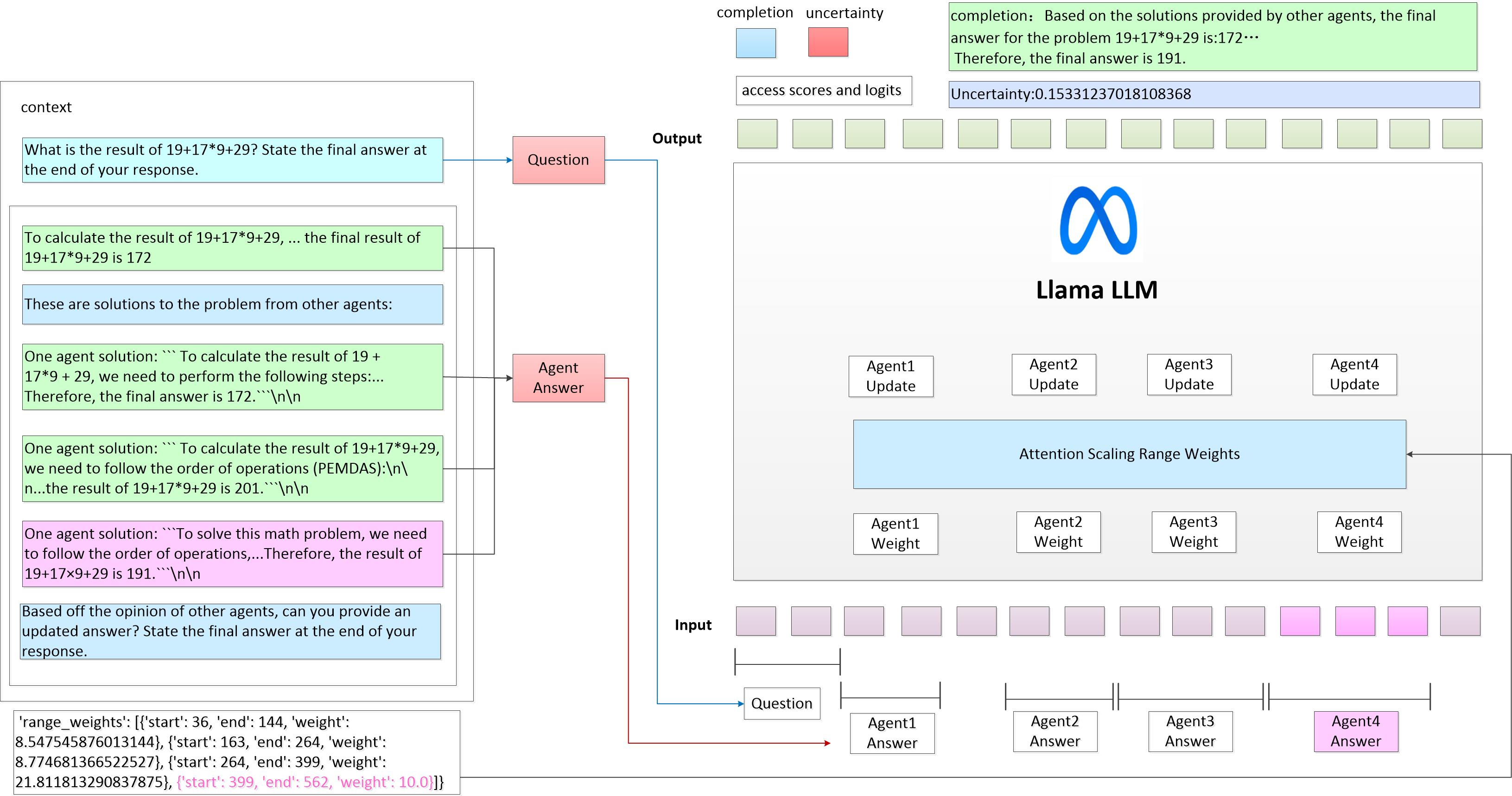
The workflow of the proposed fine-grained reasoning method. It shows the interaction between the user question, the dialogue agents, and the attention weight update mechanism.
Evaluation Highlights
- Achieved 94.0% accuracy on an arithmetic dataset, outperforming the standard multi-agent baseline (47.8%)
- Surpassed previous uncertainty-based methods like TokenSAR (50.0%) and Entropy-based attention (51.8%) by a significant margin
- Demonstrated that attention scaling based on third-party confidence (Attn-All) yields higher accuracy than standard oracle methods (73.2%)
Breakthrough Assessment
4/10
Shows a very large improvement on a specific arithmetic task, but the dataset is small (100 samples) and the scope is limited to arithmetic. The mechanism of attention scaling based on external confidence is interesting but needs broader validation.