📝 Paper Summary
Knowledge Editing Evaluation
Hallucination Correction
HalluEditBench evaluates knowledge editing methods on pre-verified hallucinations rather than generic facts, revealing that techniques often fail to correct actual errors or degrade model capabilities in unexpected ways.
Core Problem
Existing knowledge editing benchmarks (like ZsRE, WikiBio) do not verify if the model actually hallucinates the target facts before editing, leading to distorted effectiveness scores.
Why it matters:
- If a model already knows a fact (high pre-edit accuracy), applying an edit to 'correct' it is a false premise for evaluating hallucination correction
- High post-edit scores on previous benchmarks disguise the true failure rates of editing methods when applied to real-world errors
- Side effects like damaged reasoning (portability) or susceptibility to user pressure (robustness) are insufficiently tested
Concrete Example:
A model might already correctly answer 'Who is the president of France?' (Macron). Evaluating a method's ability to 'fix' this knowledge is meaningless. HalluEditBench filters for facts the model specifically gets wrong (e.g., answering 'Ilya Sutskever' instead of 'Jakub Pachocki' for OpenAI's Chief Scientist) to test true correction.
Key Novelty
HalluEditBench (Verified Hallucination Benchmark)
- Constructs a dataset where every target fact is confirmed to be hallucinated by the specific LLM (Llama-2, Llama-3, Mistral) before any editing occurs, ensuring a strict 0% pre-edit baseline
- Evaluates editing methods across five distinct facets: Efficacy (did it fix the error?), Generalization (rephrased questions), Portability (multi-hop reasoning), Locality (side effects), and Robustness (resistance to user challenge)
Architecture

The construction pipeline of HalluEditBench, illustrating the two phases: Hallucination Collection and Evaluation QA Generation.
Evaluation Highlights
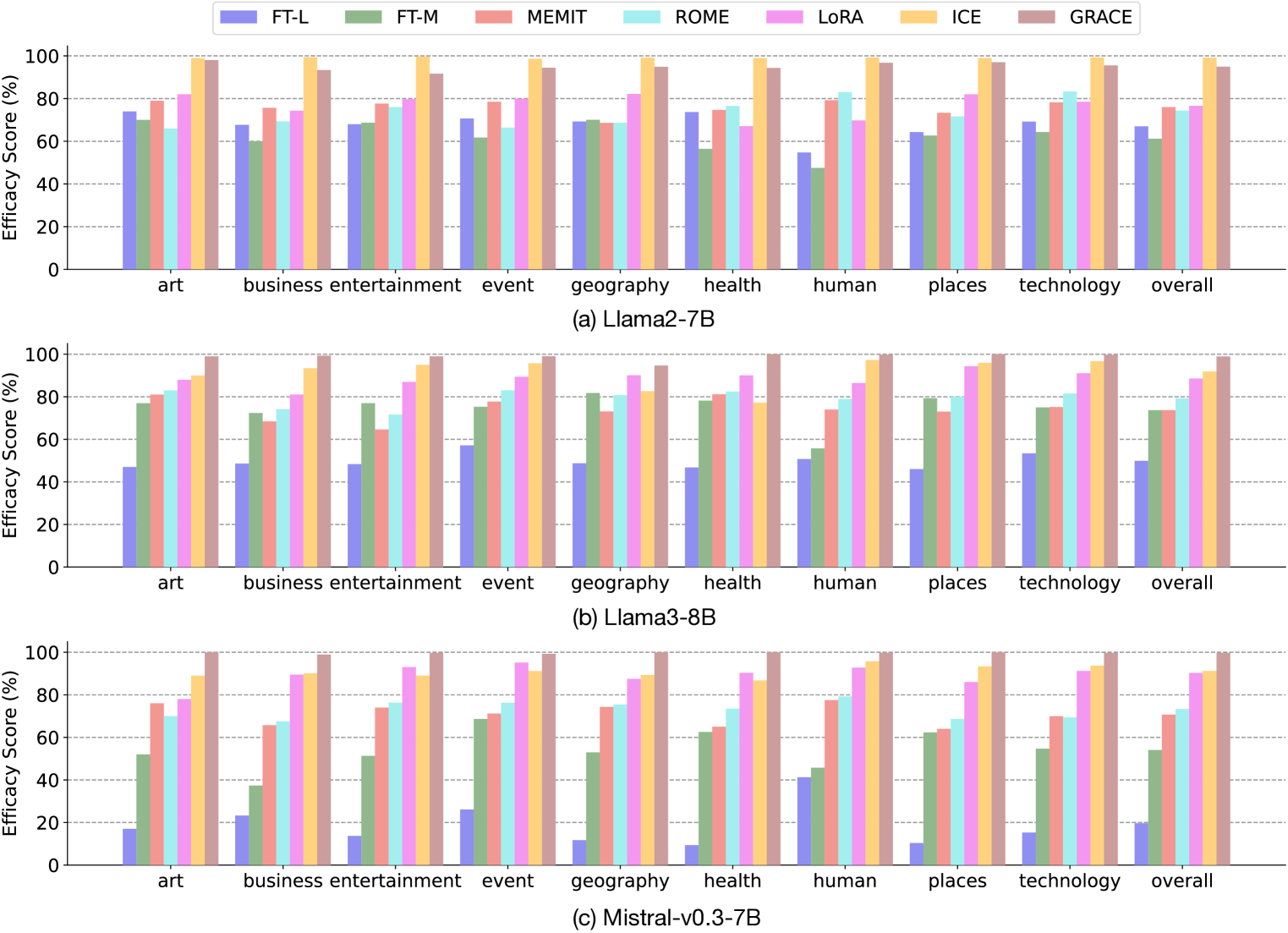
- Common methods like FT-M and MEMIT show ~100% efficacy on old benchmarks but drop to ~60% on verified hallucinations in HalluEditBench
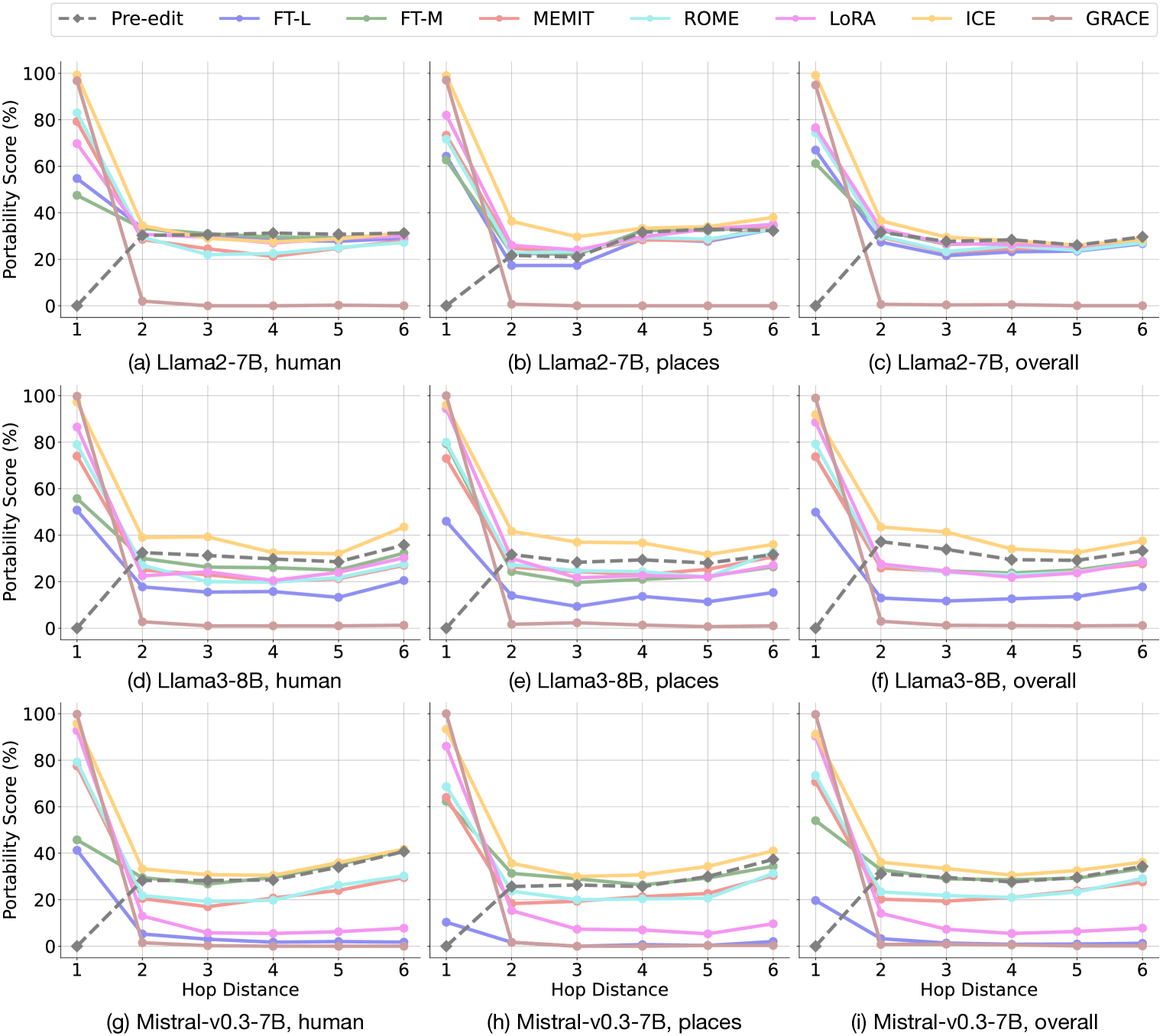
- Knowledge editing often harms reasoning: most methods (except ICE) lower performance on multi-hop questions (Portability) compared to the unedited model
- Parameter-preserving methods (ICE, GRACE) significantly outperform parameter-modifying methods (ROME, MEMIT, FT) in correcting hallucinations (Efficacy)
Breakthrough Assessment
8/10
Crucial methodological correction for the field. It exposes that current editing methods are far less effective on *actual* errors than previously thought, likely shifting future evaluation standards.