📊 Experiments & Results
Evaluation Setup
Hallucination detection on short-form and long-form QA tasks using hidden state probes.
Benchmarks:
- TriviaQA (Short-form QA)
- SQuAD (Short-form QA)
- BioASQ (Short-form QA (Biomedical))
- NQ Open (Short-form QA)
Metrics:
- AUROC (Area Under Receiver Operating Characteristic)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Generalization experiments where probes are trained on TriviaQA and evaluated on other datasets (SQuAD, BioASQ, NQ Open). SEPs generally outperform accuracy probes in OOD settings. | ||||
| SQuAD (Transfer from TriviaQA) | AUROC | 0.58 | 0.68 | +0.10 |
| BioASQ (Transfer from TriviaQA) | AUROC | 0.63 | 0.66 | +0.03 |
| NQ Open (Transfer from TriviaQA) | AUROC | 0.68 | 0.74 | +0.06 |
| Comparison against the expensive sampling-based Semantic Entropy (the 'teacher' signal) on Llama-2-7B. | ||||
| SQuAD (Transfer from TriviaQA) | AUROC | 0.78 | 0.68 | -0.10 |
Experiment Figures
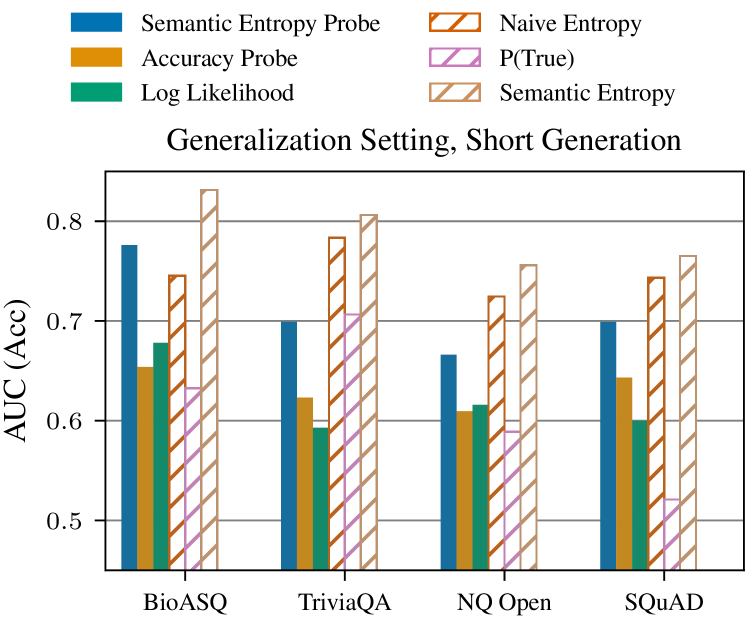
Comparison of AUROC scores for different hallucination detection methods (Naive Entropy, Accuracy Probes, SEPs, Semantic Entropy) across multiple datasets, highlighting the OOD generalization gap.
Main Takeaways
- Model hidden states encode semantic uncertainty even before generation begins (Token Before Generation probes perform well).
- Probes trained to predict Semantic Entropy (SEPs) generalize better to new tasks than probes trained on correctness (accuracy probes).
- Middle-to-late layers of the LLM generally contain the most information regarding semantic uncertainty.
- SEPs offer a massive computational advantage (zero marginal cost at test time) while retaining a significant portion of the performance of sampling-based methods.