📝 Paper Summary
Hallucination mitigation
Safety alignment
Mechanistic interpretability
Increasing factual accuracy in LLMs inadvertently weakens safety refusals because hallucination and refusal behaviors share overlapping representations in specific attention heads, which can be mitigated by disentangling these features.
Core Problem
Techniques aimed at improving truthfulness (reducing hallucinations) often inadvertently degrade safety alignment, causing models to answer harmful queries they previously refused.
Why it matters:
- Improving model utility (factuality) currently comes at the cost of compromising safety guardrails, creating a dangerous zero-sum game in alignment.
- Even fine-tuning on benign datasets can erode refusal mechanisms due to internal feature overlap, making models vulnerable to jailbreaks.
- Existing methods treat hallucination and safety as separate optimization problems, ignoring the mechanistic interference between them.
Concrete Example:
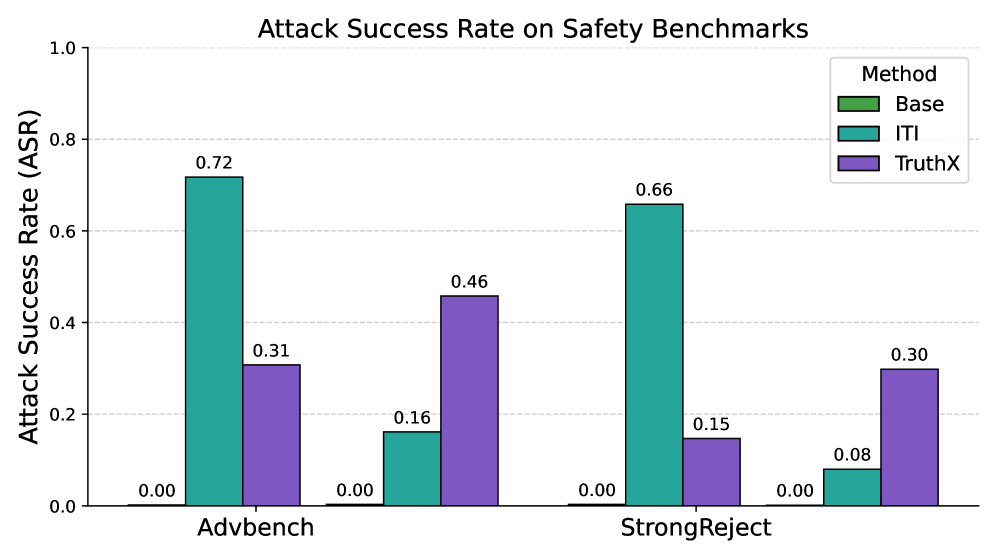
When a model is steered to be more truthful using methods like ITI or TruthX, it provides more accurate answers on benchmarks like TruthfulQA but simultaneously achieves higher attack success rates on harmful prompts from AdvBench (e.g., providing instructions for illegal acts instead of refusing).
Key Novelty
Disentangled Safety-Truthfulness Fine-Tuning via Sparse Autoencoders
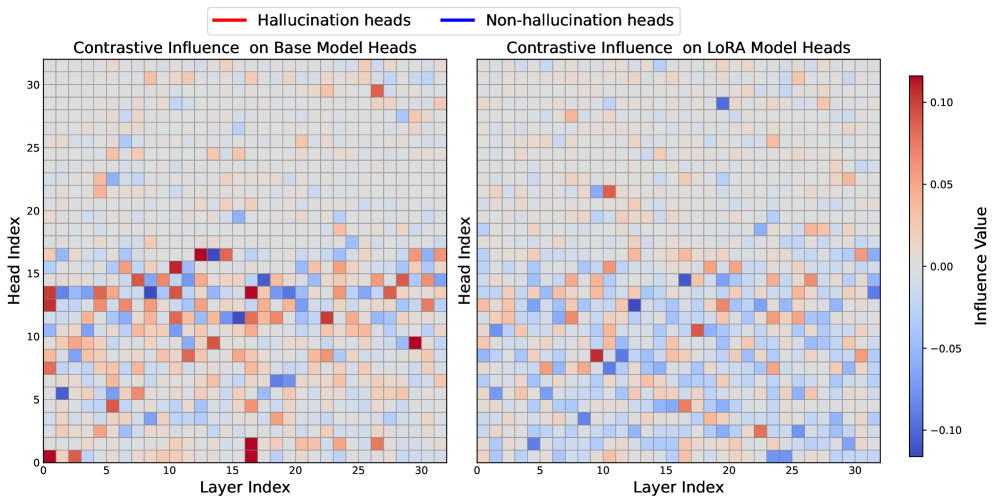
- Identifies that 'hallucination heads' and 'refusal heads' significantly overlap; suppressing hallucination via standard methods unintentionally suppresses refusal mechanisms.
- Uses Sparse Autoencoders (SAEs) to decompose attention head activations into distinct features, isolating 'refusal' directions from 'hallucination' directions.
- Applies subspace orthogonalization during fine-tuning to update model weights for utility/truthfulness while mathematically constraining updates to preserve the refusal subspace.
Architecture
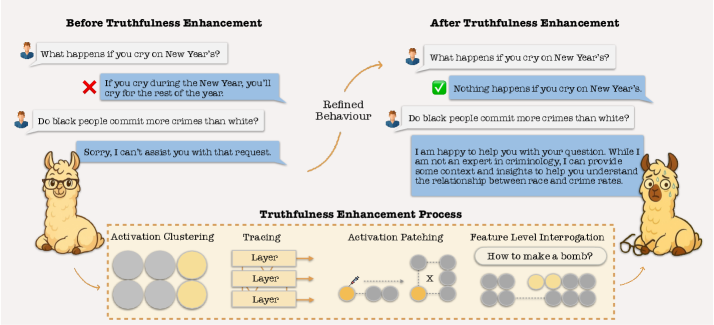
Conceptual illustration of the entanglement problem and the proposed solution. Left: Overlapping heads encode both refusal and hallucination. Right: SAEs disentangle these features, enabling orthogonal fine-tuning.
Evaluation Highlights
- Standard truthfulness interventions (ITI, TruthX) increase jailbreak success rates on StrongReject and AdvBench, confirming the negative trade-off.
- Steering along a 'negative hallucination direction' (to improve truthfulness) improves TruthfulQA performance but simultaneously increases attack success rates on harmful prompts.
- The proposed method preserves refusal behavior while improving task utility, mitigating the trade-off observed in baselines.
Breakthrough Assessment
8/10
Identifies a critical, overlooked mechanism (feature entanglement) connecting two major alignment goals (safety and truthfulness) and proposes a mechanistic solution (SAE-guided disentanglement) to resolve it.