📝 Paper Summary
Hallucination mitigation
Zero-shot reasoning
HalluClean is a zero-shot, task-agnostic framework that guides LLMs to detect and correct their own hallucinations through a structured four-step reasoning process without external knowledge.
Core Problem
LLMs frequently generate factually incorrect or hallucinatory content across various tasks, but existing solutions either require expensive external retrieval or task-specific supervised training data.
Why it matters:
- Retrieval-based methods fail when external knowledge sources are unavailable, inaccurate, or costly to access
- Supervised detection methods struggle to generalize to new hallucination types or domains due to reliance on specific labeled datasets
- Hallucinations vary widely across tasks (e.g., math vs. dialogue), making narrow, task-specific solutions hard to scale
Concrete Example:
In a math word problem, an LLM might generate a solution where a variable (e.g., number of apples) is negative, violating logic. A standard model might overlook this, whereas HalluClean's planning step explicitly prompts the model to check constraints, identifying the 'negative quantity' error before revising.
Key Novelty
Reasoning-Enhanced Zero-Shot Correction (HalluClean)
- Decomposes the hallucination mitigation process into explicit planning, execution, and revision phases using a single LLM without fine-tuning
- Uses 'task-routing prompts'—minimal descriptions that adapt the reasoning strategy to the specific task (e.g., checking for contradictions vs. checking for math errors) automatically
Architecture
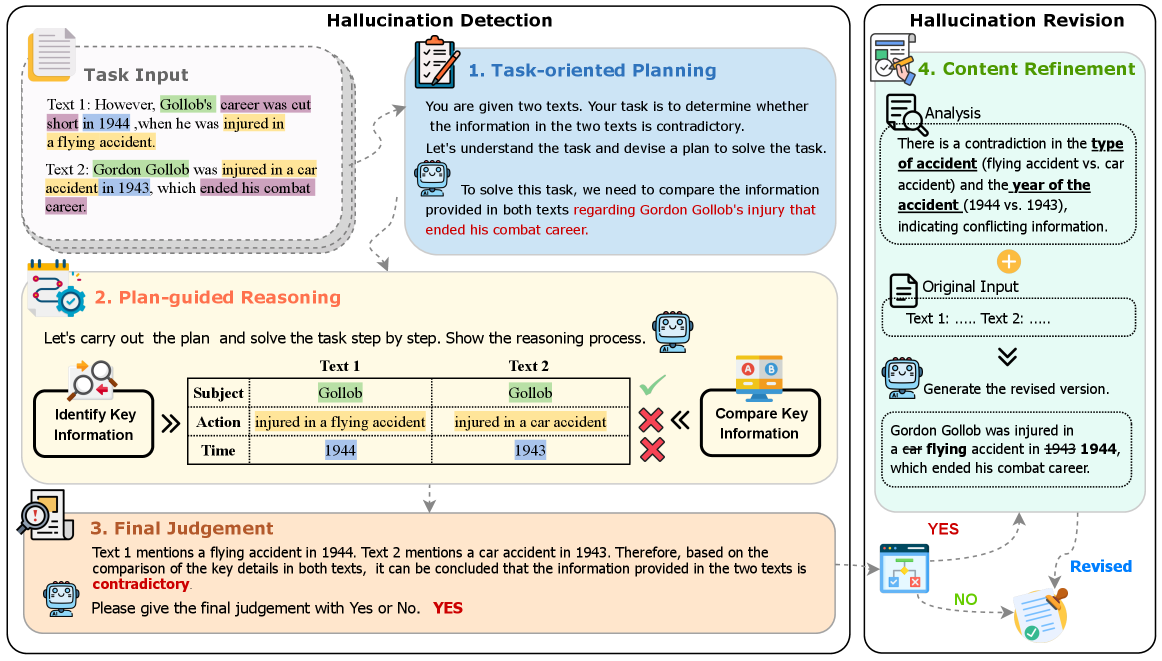
Overview of the HalluClean framework architecture, illustrating the flow from input to revised output.
Evaluation Highlights
- Significantly improves factual consistency across five diverse tasks: QA, Dialogue, Summarization, Math Word Problems, and Contradiction Detection
- Achieves strong zero-shot performance on the HaluBench domain-specific benchmark (Medical and Finance) without domain-specific training
- Demonstrates effective self-correction capabilities where the model uses its own reasoning traces to guide the revision process
Breakthrough Assessment
7/10
Offers a practical, lightweight solution for hallucination that requires no training or retrieval. While conceptually simple (prompt engineering), its broad applicability and structured reasoning approach make it highly deployable.