📊 Experiments & Results
Evaluation Setup
Mathematical reasoning and factual QA with adaptive abstention
Benchmarks:
- BeyondAIME (Mathematical reasoning (In-domain))
- SimpleQA (Factual QA (Cross-domain))
Metrics:
- Signal-to-Noise Ratio (SNR)
- Log-scale SNR Gain
- True Positive (TP) Rate
- False Negative (FN) Rate
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| SNR gain analysis shows the proposed method allows a small 4B model to outperform much larger frontier models in calibration effectiveness. | ||||
| BeyondAIME | Log-scale SNR Gain | 0.207 | 0.806 | +0.599 |
| BeyondAIME | Log-scale SNR Gain | 0.019 | 0.183 | +0.164 |
Experiment Figures
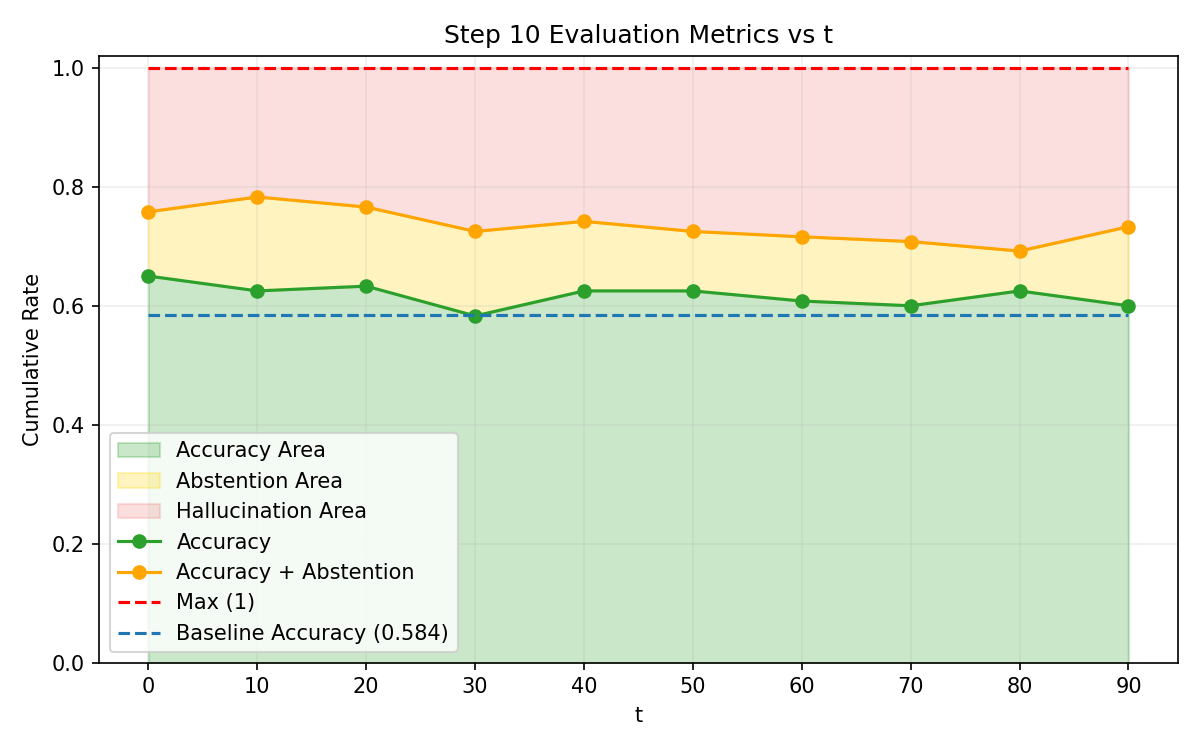
Comparison of Explicit Risk Thresholding vs. Verbalized Confidence

Critic Value failure cases in mathematical reasoning
Main Takeaways
- Verbalized Confidence with proper scoring rules significantly outperforms explicit risk thresholding (conditioning on t) by creating a smoother optimization landscape
- Critic Value is a strong baseline for response-level uncertainty but fails at claim-level granularity because it predicts final success
- Smaller models (4B) can be trained to be more 'honest' than frontier models, proving calibration is a transferable meta-skill decoupled from raw accuracy
- Confidence estimates from the method serve as effective reward proxies for test-time scaling, outperforming majority voting