📝 Paper Summary
Hallucination detection
Mechanistic interpretability
Internal state probing
The paper reveals that LLMs encode truthfulness through two distinct pathways—one relying on question-answer information flow and another deriving evidence solely from the generated answer—and proposes detection methods exploiting this distinction.
Core Problem
While internal LLM representations are known to encode truthfulness signals, the specific mechanisms by which these signals arise and operate remain largely unexplored.
Why it matters:
- Understanding the origin of truthfulness cues is crucial for building reliable generative systems, as black-box detection methods often fail to explain underlying causes
- Current internal probing methods treat all signals uniformly, potentially missing nuances in how models process well-known facts versus long-tail knowledge
Concrete Example:
When a model answers 'Columbia' for the capital of South Carolina, it might rely on the specific question context (Q-Anchored). However, for other facts, it might generate an answer and then self-validate it independently of the question (A-Anchored). Treating these mechanisms identically limits detection accuracy.
Key Novelty
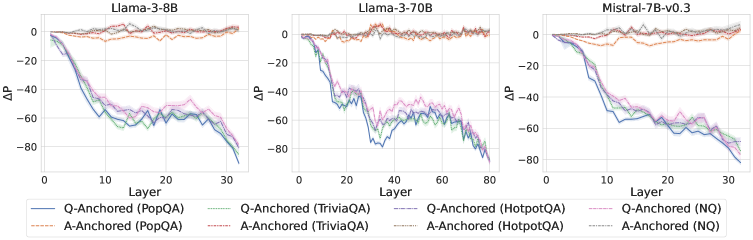
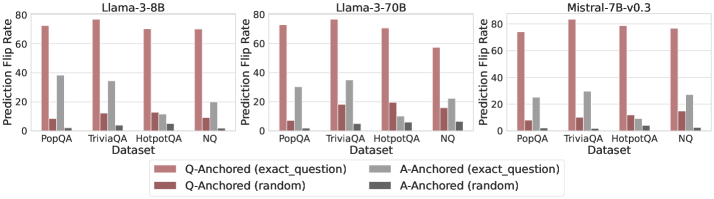
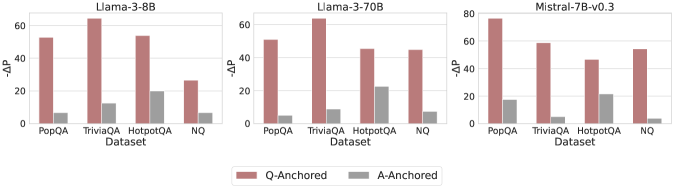
Two distinct truthfulness pathways: Question-Anchored (Q-Anchored) and Answer-Anchored (A-Anchored)
- Q-Anchored pathway: Truthfulness signals depend heavily on the information flow from the exact question tokens to the answer
- A-Anchored pathway: Truthfulness signals are self-contained within the generated answer and remain robust even when question information is blocked or removed
- Mixture-of-Probes (MoP) & Pathway Reweighting (PR): New detection strategies that train specialized classifiers for each pathway or amplify pathway-specific signals
Architecture
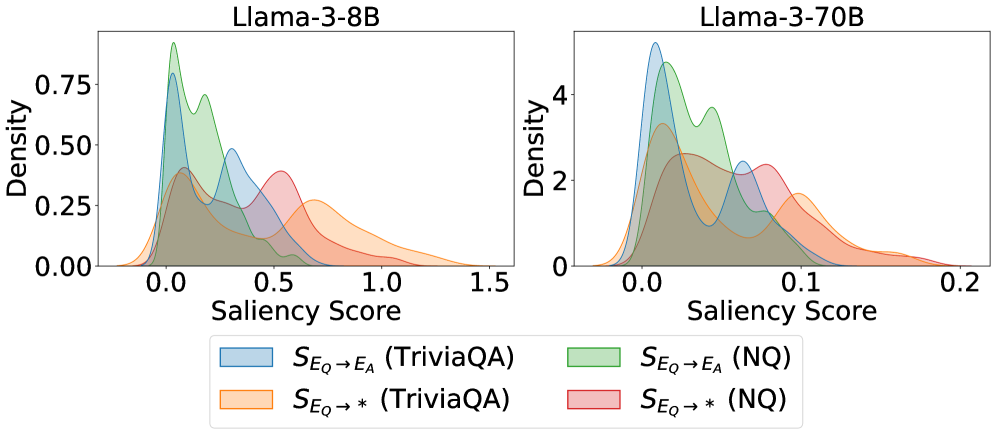
Saliency distribution of attention from Exact Question tokens to Answer tokens, showing a bimodal distribution.
Evaluation Highlights
- Achieves up to 10% AUC gain in hallucination detection across various datasets and models using the proposed pathway-aware methods
- Demonstrates that Q-Anchored encoding dominates for well-known facts (within knowledge boundaries), while A-Anchored encoding is favored for long-tail cases
- Saliency analysis reveals a bimodal distribution in attention dependency, statistically confirming the existence of two distinct mechanisms
Breakthrough Assessment
8/10
Provides significant mechanistic insight into LLM hallucinations by identifying two distinct encoding pathways. The findings are well-supported by ablation studies and lead to practical improvements in detection.