📝 Paper Summary
Uncertainty Estimation
Hallucination Detection
A fast, memory-efficient deep ensemble method that fine-tunes pre-trained LLMs using shared weights and rank-one fast weights (via BatchEnsemble and LoRA) to detect hallucinations accurately.
Core Problem
Deep ensembles provide robust uncertainty estimates for hallucination detection but are computationally prohibitive for Large Language Models (LLMs) due to the need to train and store multiple large models.
Why it matters:
- LLMs frequently hallucinate (deviate from instructions or facts), posing severe risks in safety-critical fields like healthcare
- Sample-based uncertainty methods often fail to capture true model uncertainty compared to ensembles
- Existing ensemble methods for LLMs require massive compute resources, making them impractical for most practitioners
Concrete Example:
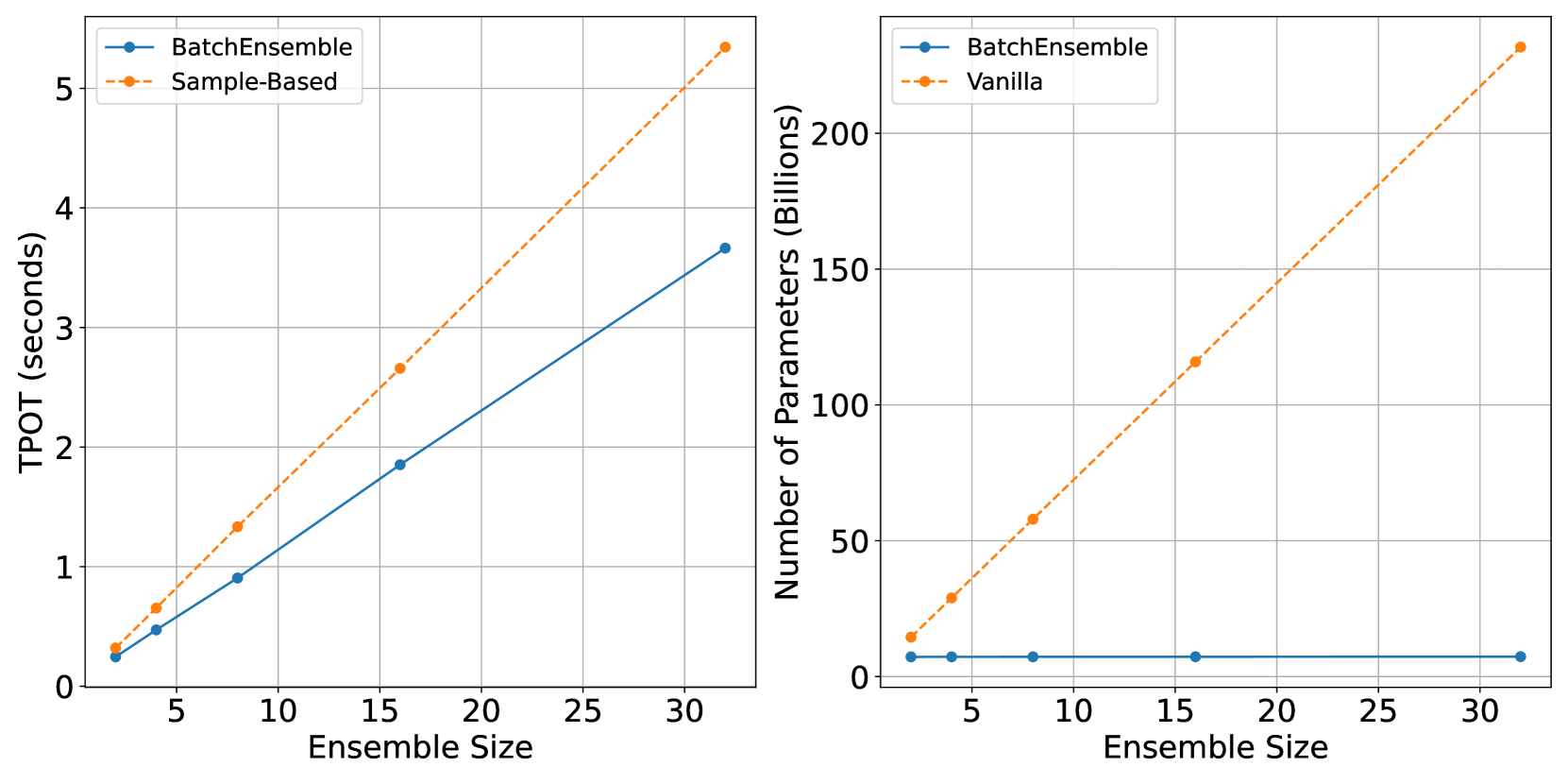
When an LLM is asked a question not in its context (e.g., an unanswerable SQuAD 2.0 question), a single model might confidently invent an answer. A standard deep ensemble would detect this high uncertainty but requires 4x-10x the memory. The proposed method detects the high uncertainty using only one GPU.
Key Novelty
LoRA-based BatchEnsemble for LLMs
- Adapt BatchEnsemble to fine-tune pre-trained LLMs rather than training from scratch, using LoRA to minimize trainable parameters
- Represent each ensemble member using a single shared pre-trained weight matrix multiplied elementwise by member-specific rank-one 'fast weights'
- Reformulate hallucination detection as a binary classification task using uncertainty metrics derived from this memory-efficient ensemble
Architecture
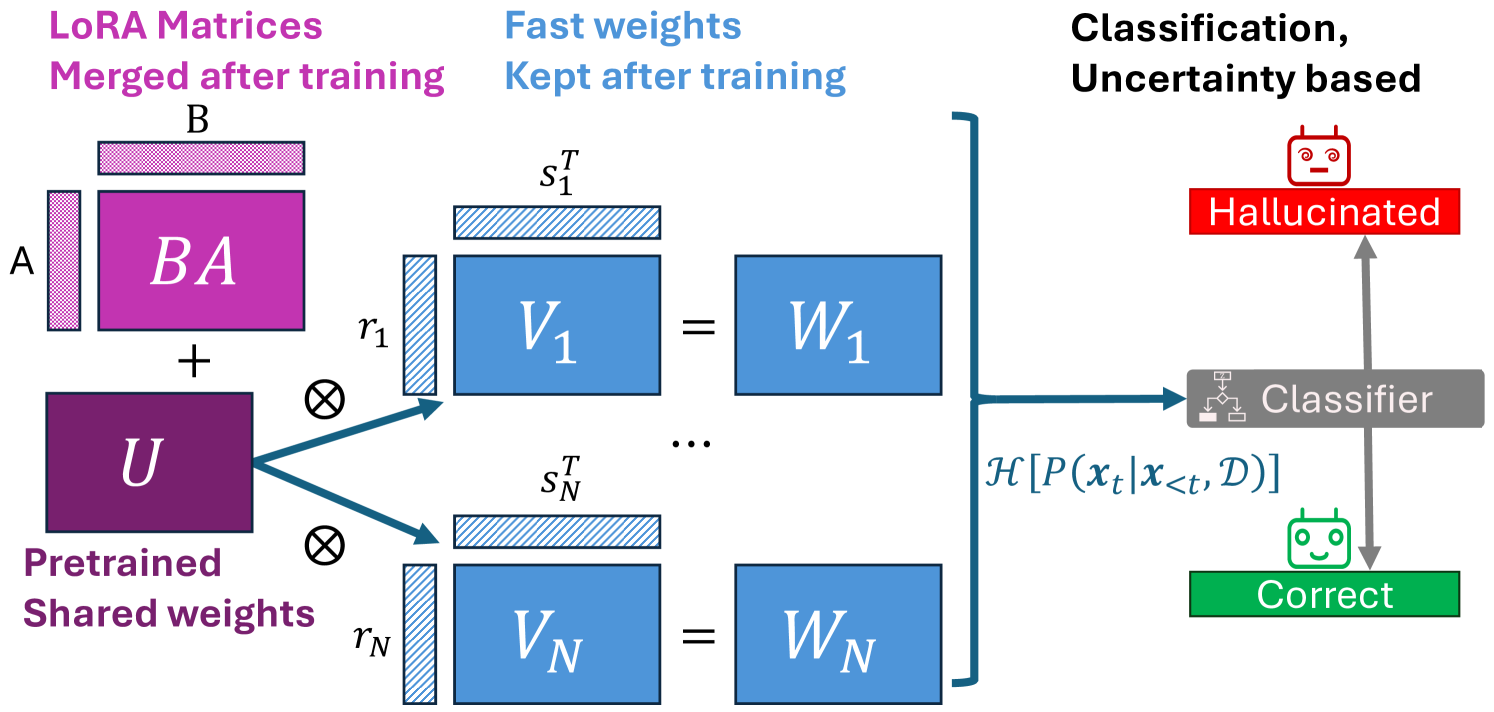
The proposed BatchEnsemble architecture applied to a pre-trained LLM with LoRA
Evaluation Highlights
- Achieves 97.8% accuracy in detecting faithfulness hallucinations on SQuAD 2.0, outperforming sample-based baselines
- Attains 68% accuracy in detecting factual hallucinations on MMLU without compromising predictive performance
- Reduces memory complexity from linear O(M) to near-constant O(1) per added ensemble member, enabling training on a single A40 GPU
Breakthrough Assessment
7/10
Significant practical contribution by making deep ensembles feasible for LLMs on single GPUs. Performance is strong on faithfulness hallucinations, though factual hallucination detection shows mixed results against heavy-regularization baselines.