📝 Paper Summary
Code Generation
Hallucination Detection
The paper introduces the concept of code hallucination—code that is syntactically correct but functionally flawed—and provides a taxonomy, a dynamic detection algorithm, and a benchmark to evaluate LLMs.
Core Problem
LLMs often generate code that is syntactically correct and semantically plausible but fails to execute as expected or meet requirements, a phenomenon distinct from simple syntax errors.
Why it matters:
- Code value is only realized upon successful execution and testing; NL hallucination definitions do not directly apply to executable code
- Hallucinated code can trigger runtime errors or functional defects, hindering reliable deployment in automated software development
- Current benchmarks focus on pass rates (performance) rather than systematically categorizing and quantifying the *types* of non-syntax errors (hallucinations)
Concrete Example:
A model might generate code that enters an infinite loop (e.g., repeatedly calling a function) due to logical collapse, eventually hitting a token limit. While this manifests as a SyntaxError or Timeout, the root cause is a 'Logical Hallucination', distinct from a simple typo like an undefined variable name.
Key Novelty
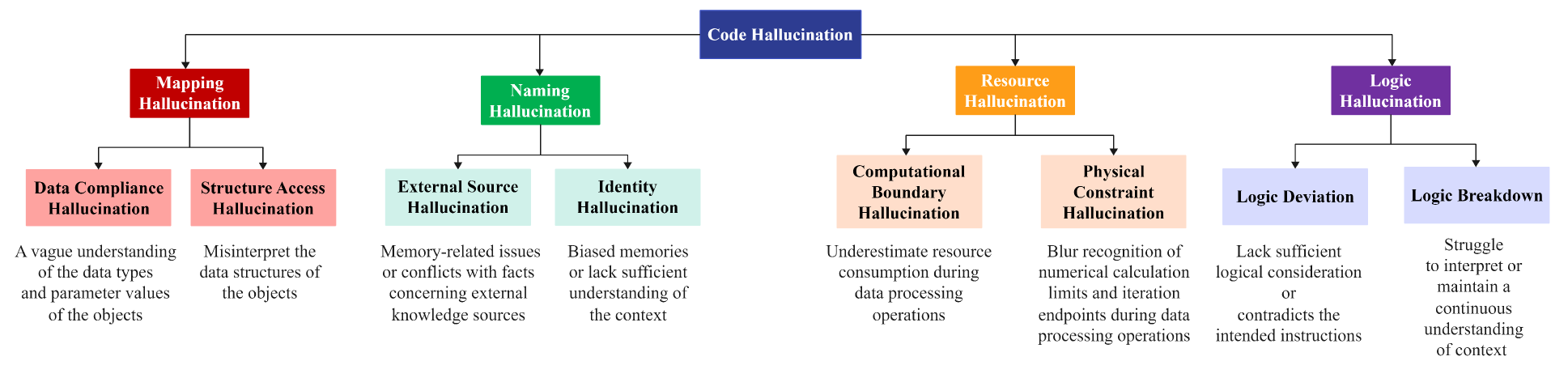
Execution-based Code Hallucination Taxonomy & Detection
- Defines 'code hallucination' specifically as code that may be syntactically correct but fails verification, distinguishing it from simple code errors
- Categorizes hallucinations into four main types (Mapping, Naming, Resource, Logic) using a two-stage heuristic approach
- Uses a statistical induction method (CodeHalu) that executes code across multiple iterations to identify persistent failure patterns
Architecture
The CodeHalu detection process: Validation -> Identification -> Construction.
Evaluation Highlights
- Average cross-task occurrence rate of hallucination categories is low (2.04%), confirming the independence of the proposed taxonomy
- Even for Gemma-7B (which exhibited severe hallucinations), only 1.07% of task samples showed cross-task hallucinations
- Evaluation of 16 LLMs on 105,958 samples showed an exceptionally low average syntax error rate of 0.0020, confirming that most generated code is syntactically valid but potentially hallucinated
Breakthrough Assessment
7/10
Establishes a necessary formal definition and taxonomy for code hallucinations, distinct from NLP hallucinations. The benchmark and detection algorithm are valuable tools, though the approach is primarily diagnostic.
