📝 Paper Summary
Uncertainty Quantification (UQ)
Hallucination Detection
The paper introduces pre-trained Transformer-based Uncertainty Quantification (UQ) heads that attach to frozen LLMs, using attention maps and token probabilities to detect claim-level hallucinations more effectively than unsupervised methods.
Core Problem
LLMs frequently hallucinate convincing but false information, and users lack tools to detect these errors. Existing UQ methods are either unsupervised (weak performance) or supervised but rely on outdated architectures (linear probes/MLPs) and limited features.
Why it matters:
- Hallucinations undermine trust in LLM applications, risking the spread of misleading information to users
- Unsupervised methods struggle with the infinite nature of text generation and token interdependencies
- Previous supervised attempts (SAPLMA, Factoscope) often fail to generalize across domains or require complex, inefficient feature engineering
Concrete Example:
When an LLM generates a biography, it might hallucinate a specific date or award. While the token probability for the year might be slightly low, unsupervised methods often miss this context. The proposed UQ head, by analyzing attention patterns (e.g., the model attending to its own generations rather than the prompt), can flag the specific claim 'won the award in 1999' as uncertain.
Key Novelty
Transformer-based Uncertainty Quantification (UQ) Heads
- Attaches a lightweight Transformer encoder to a frozen LLM to process internal states during generation without retraining the LLM itself
- Leverages a specific combination of features: flattened attention maps (capturing how the model attends to prompt vs. generation) and top-token probabilities
- Operates at the sub-sentence 'atomic claim' level rather than just flagging entire sequences
Architecture
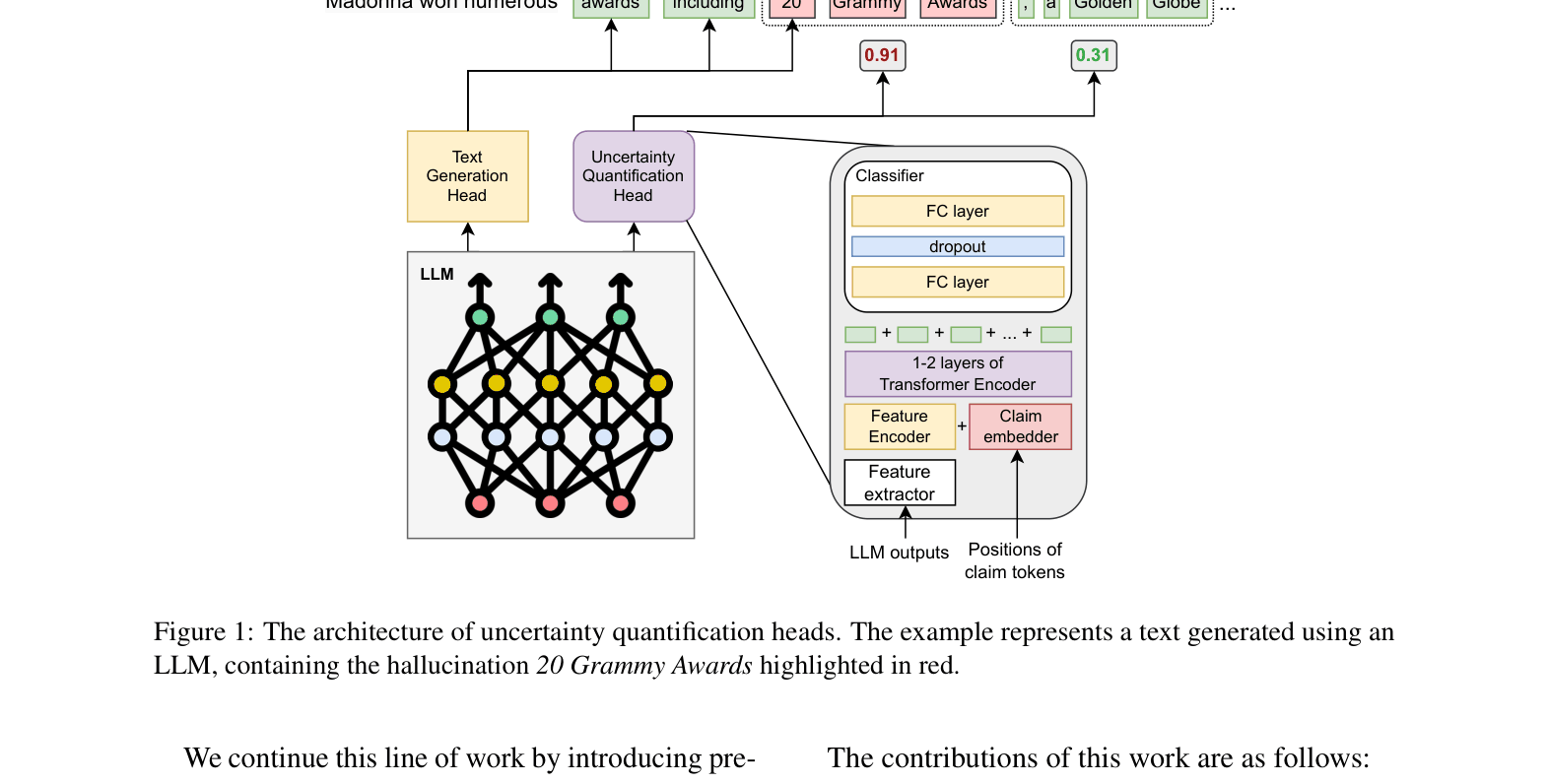
The architecture of the Uncertainty Quantification (UQ) head attached to the LLM.
Evaluation Highlights
- Achieves state-of-the-art performance in claim-level hallucination detection, outperforming Factoscope and LookbackLens across in-domain and out-of-domain prompts
- Demonstrates strong cross-lingual generalization to languages not seen during training
- Releases a collection of pre-trained heads for Llama, Gemma 2, and Mistral-v0.2 series models
Breakthrough Assessment
8/10
Significant practical contribution by releasing plug-and-play UQ heads that outperform existing methods. The shift to Transformer-based heads with attention features addresses key limitations of linear probes.