📝 Paper Summary
Hallucination suppression
Uncertainty quantification
SINdex detects hallucinations by clustering multiple LLM responses based on semantic embeddings and calculating a novel inconsistency score that penalizes both cluster dispersion and lack of internal coherence.
Core Problem
Existing semantic entropy methods for hallucination detection rely on computationally expensive NLI models that often struggle with nuanced semantic similarity, leading to inaccurate uncertainty estimation.
Why it matters:
- LLMs frequently generate plausible but factually incorrect information (hallucinations), posing risks in sensitive domains like medicine and law.
- Current NLI-based methods are slow and computationally intensive, making them difficult to scale for real-time applications.
- Strict entailment checks in NLI can fail to group semantically similar but syntactically distinct sentences (e.g., negations vs. assertions), leading to fragmented clusters and false uncertainty signals.
Concrete Example:
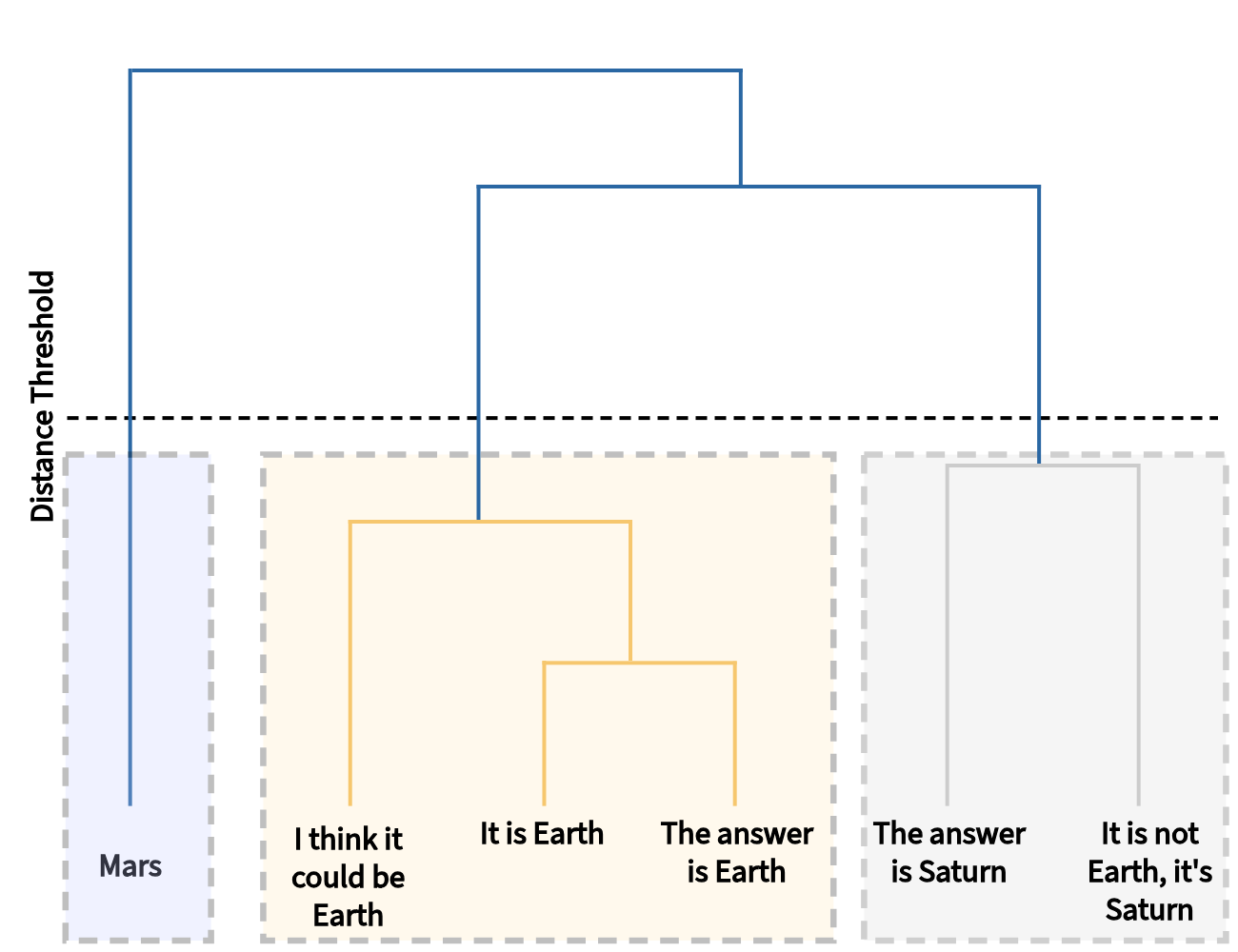
For the question 'Which is the third planet from the sun?', responses like 'It is Earth' and 'I think it could be Earth' should be clustered together. NLI-based methods might separate them because 'I think...' does not strictly entail 'It is...', whereas SINdex's embedding-based clustering correctly groups them, recognizing the shared semantic core.
Key Novelty
SINdex (Semantic INconsistency Index)
- Replaces NLI-based entailment checks with sentence embeddings and hierarchical agglomerative clustering to group responses based on semantic similarity.
- Introduces a new inconsistency measure (SINdex) that adjusts standard entropy by weighing it against intra-cluster coherence (cosine similarity), ensuring that tight, consistent clusters yield lower uncertainty scores than loose, vague ones.
Architecture
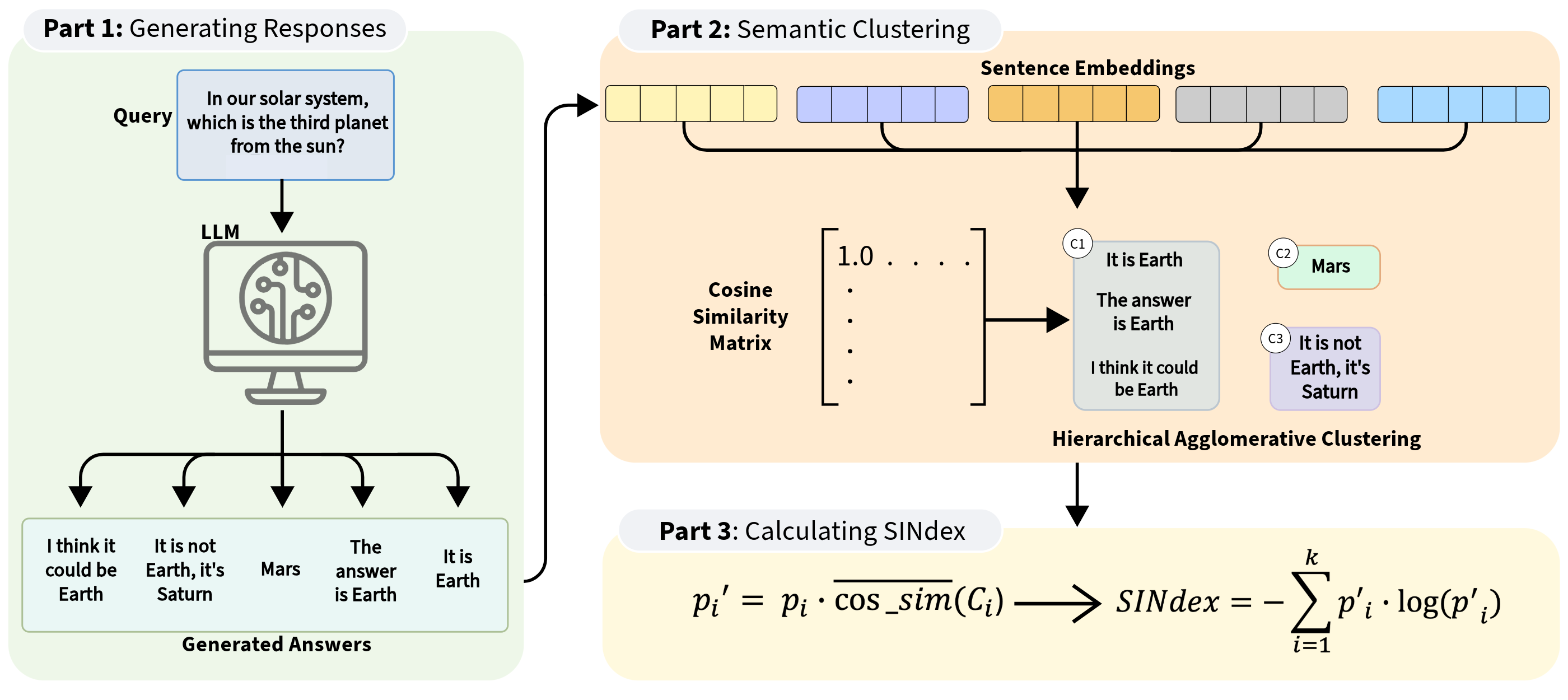
Overview of the SINdex framework.
Evaluation Highlights
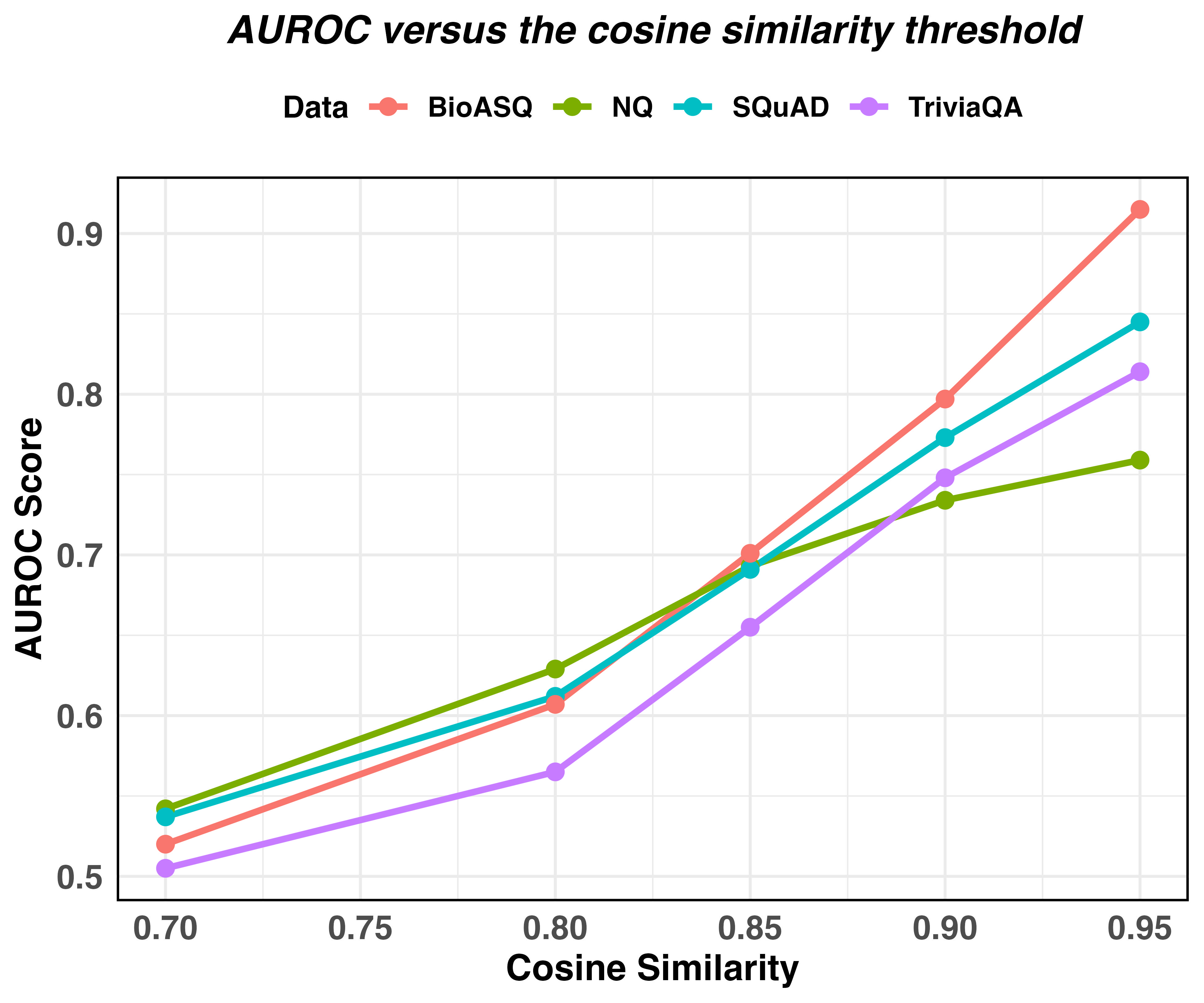
- Achieves up to 9.3% improvement in AUROC for hallucination detection compared to state-of-the-art Semantic Entropy methods on benchmarks like TriviaQA and BioASQ.
- Demonstrates a 60-fold speedup in processing time compared to NLI-based approaches when analyzing 200 generations, due to efficient embedding clustering.
- Consistent performance gains across both open-book (SQuAD) and closed-book (TriviaQA, NQ) QA datasets using Llama-2-7b-chat.
Breakthrough Assessment
7/10
Significant efficiency gains (60x) and solid performance improvements make this a practical contribution. It simplifies the semantic entropy pipeline by removing the heavy NLI dependency.