📝 Paper Summary
Hallucination suppression
Multi-agent debate
CFMAD reduces hallucinations by forcing LLMs to generate counterfactual justifications for every possible answer option, then debating their validity with a critic to overcome inherent biases.
Core Problem
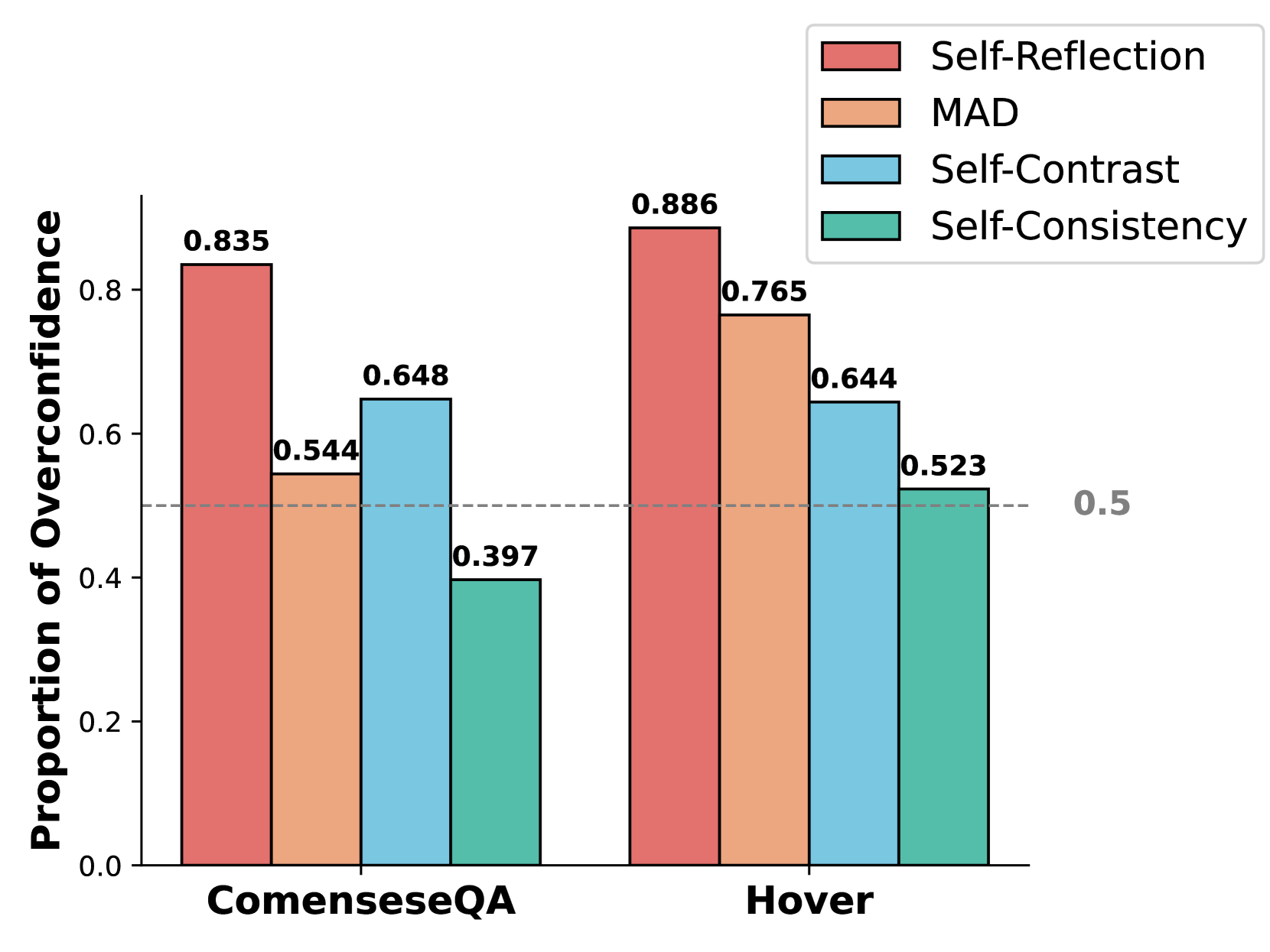
Self-correction and diverse sampling methods often fail because LLMs are overconfident in their initial incorrect answers due to inherent biases and beliefs.
Why it matters:
- Existing methods like self-reflection simply reinforce the model's initial error rather than correcting it (the 'overconfidence issue').
- Diverse sampling limits exploration because models repeatedly generate the same incorrect answers based on their internal probability distributions.
- Without external intervention or a mindset shift, LLMs struggle to inspect answers they wouldn't naturally consider.
Concrete Example:
In a multiple-choice question, if an LLM wrongly believes 'A' is correct, self-correction prompts usually result in the model defending 'A'. Even sampling multiple times often yields 'A' repeatedly. CFMAD forces the model to assume 'B', 'C', and 'D' are correct and generate reasons why, exposing weak logic for incorrect options.
Key Novelty
Counterfactual Multi-Agent Debate (CFMAD)
- Presets specific stances for multiple agents, compelling them to hallucinate justifications for every answer option (even incorrect ones) to override inherent bias.
- Pairs each 'believer' agent with a 'skeptical critic' agent to debate the generated justifications.
- Uses a third-party judge to evaluate the debates and identify the factual answer based on which justification withstood scrutiny.
Architecture

The CFMAD framework workflow, illustrating the two stages: Abduction Generation and Counterfactual Debate.
Evaluation Highlights
- Outperforms standard prompting by +25.5% on average across four datasets (FEVER, Hover, QuAC, CommonsenseQA).
- Surpasses multi-agent debate (MAD) baselines by significant margins (e.g., +13.1% vs MAD on Hover).
- Achieves higher accuracy than GPT-4 on CommonsenseQA (79.2% vs 75.3%) using GPT-3.5-turbo as the backbone.
Breakthrough Assessment
7/10
Strong conceptual novelty in using forced counterfactuals to break confirmation bias. Significant empirical gains over standard debate methods, though relies on computation-heavy multi-agent interactions.