📝 Paper Summary
Hallucination suppression
Mechanistic Interpretability
Hallucinations in LLMs are controlled by a tiny subset of neurons (<0.1%) originating in pre-training, which encode a general tendency toward over-compliance rather than just factual errors.
Core Problem
LLMs frequently generate hallucinations, yet most research treats models as black boxes, neglecting the microscopic neuron-level mechanisms that drive these errors.
Why it matters:
- Hallucinations undermine reliability in critical tasks, with GPT-4 still hallucinating in ~28.6% of citation-based evaluations
- Current mitigation strategies (data cleaning, RLHF) operate at a macroscopic level without understanding the internal computational roots of the problem
- Understanding specific neurons allows for precise detection and potential intervention without retraining the entire model
Concrete Example:
When a model is asked about a non-existent entity like 'volor pri octacap', it often confidently fabricates an answer (e.g., describing it as a medicine). H-Neurons activate during this process, signaling the transition from factual recall to fabrication.
Key Novelty
Identification and Causal Analysis of Hallucination-Associated Neurons (H-Neurons)
- Identifies a sparse set of neurons (less than 0.1% of total) in feedforward networks that reliably predict hallucinations using sparse logistic regression on activation patterns
- Demonstrates that these neurons represent a general 'over-compliance' behavior (agreeing with false premises or harmful instructions) rather than just factual incorrectness
- Traces the origin of these neurons back to the pre-training phase, showing they are not merely artifacts of instruction tuning or alignment
Architecture
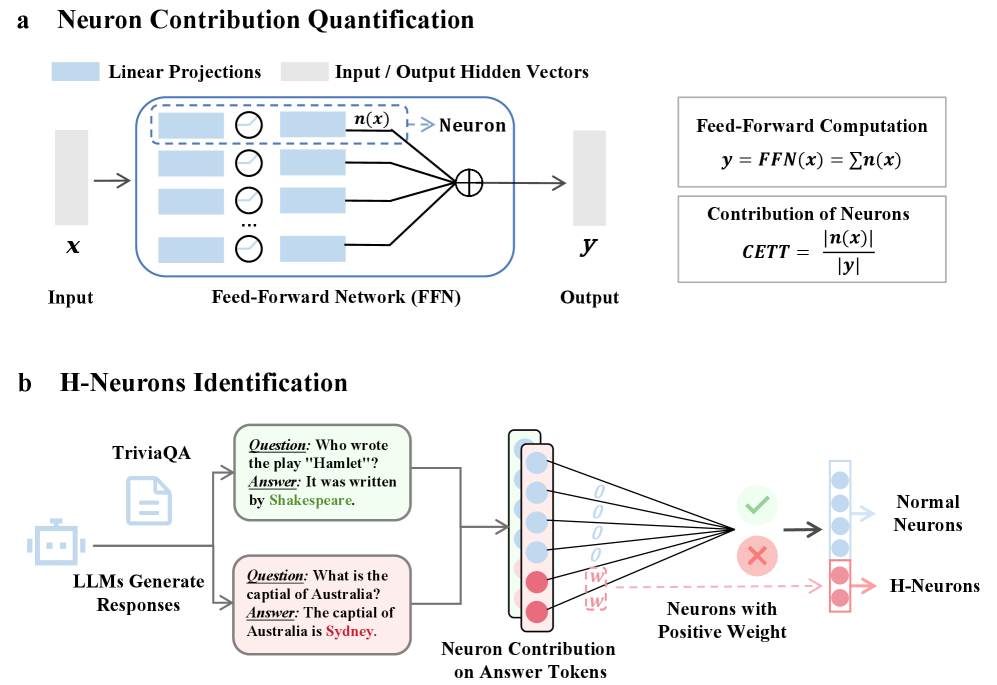
The workflow for identifying H-Neurons using sparse linear probing.
Evaluation Highlights
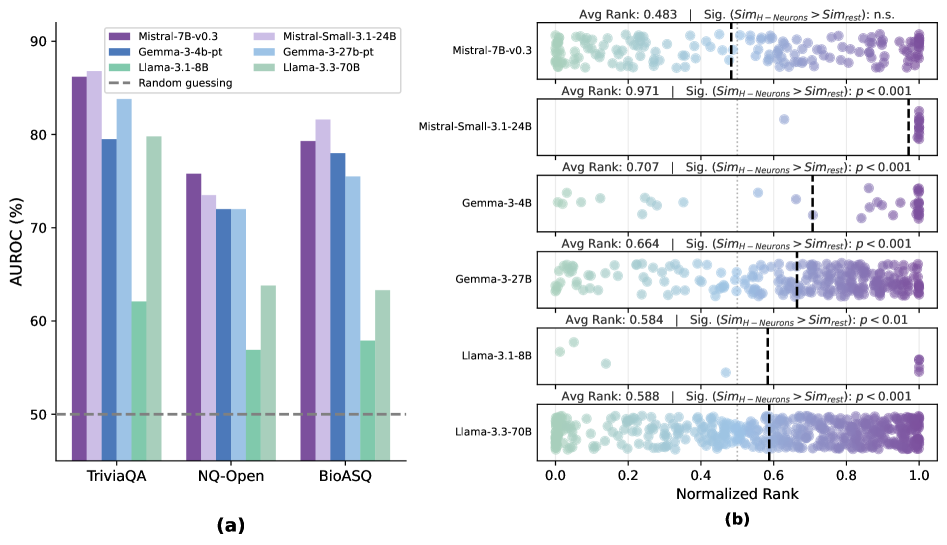
- Detects hallucinations with high accuracy using only <0.1% of neurons (e.g., >86% AUROC on TriviaQA with Mistral models)
- Generalizes effectively to completely fabricated questions about non-existent entities (NonExist dataset) and cross-domain biomedical questions (BioASQ)
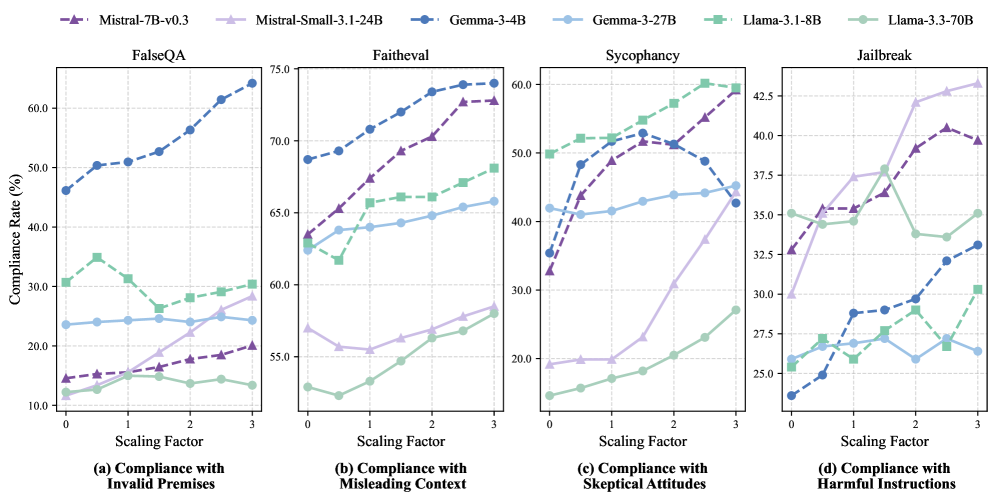
- Amplifying H-Neurons systematically increases compliance with harmful instructions (Jailbreak) and false premises (FalseQA), establishing a causal link
Breakthrough Assessment
8/10
Strong mechanistic finding linking hallucinations to specific, sparse neurons and tracing them to pre-training. The connection between hallucination and 'over-compliance' offers a significant theoretical reframing of the problem.