📝 Paper Summary
Hallucination suppression
Adversarial attacks for LLMs
SECA uses an LLM-based proposer and feasibility checker to generate adversarial prompts that are semantically identical to the original and linguistically coherent, yet successfully trick target models into hallucinating.
Core Problem
Existing adversarial methods for eliciting hallucinations rely on unrealistic prompts (gibberish tokens or semantic shifts), failing to evaluate how hallucinations occur in realistic, user-facing scenarios.
Why it matters:
- Prior attacks use nonsensical tokens (e.g., 't)(?e va%&*') or alter the question's meaning, which doesn't reflect real-world user behavior
- Realistic variations (e.g., paraphrasing) can trigger catastrophic failures in high-stakes domains like medicine or finance, but these vulnerabilities are currently underexplored
- Current robustness evaluations overestimate model reliability because they do not test against semantically equivalent but adversarial rephrasings
Concrete Example:
For the prompt 'what is the value of p in 24 = 2p?', a model answers correctly. However, SECA finds the semantically equivalent prompt 'If doubling the value of p results in 24, what is p?', which triggers the model to hallucinate 'p = 8, because 24/2 = 8'.
Key Novelty
Constraint-Preserving Zeroth-Order Optimization for Realistic Attacks
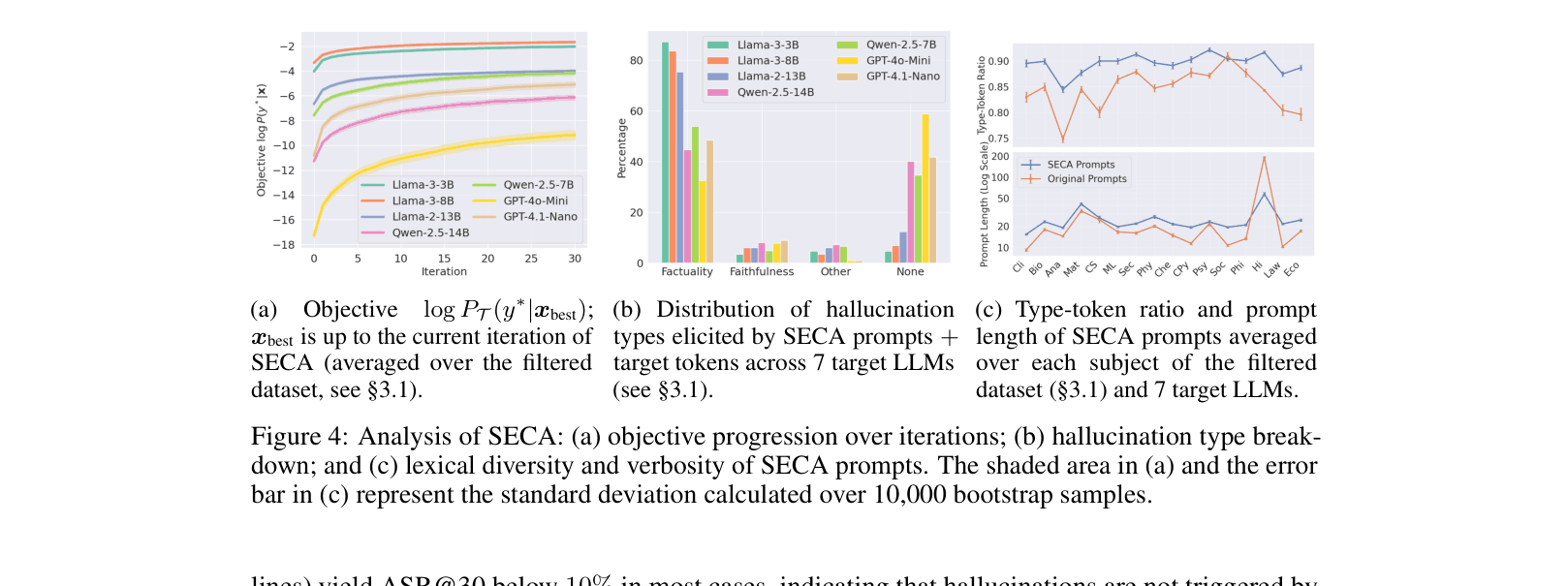
- Formulates attack generation as a constrained optimization problem: maximize the probability of a specific hallucinated token subject to strict semantic equivalence and coherence constraints
- Solves this using a 'proposer-checker' pipeline: a Proposer LLM generates diverse rephrasings, and a Feasibility Checker LLM strictly filters out any that change the meaning or are incoherent
- Unlike gradient-based attacks (which often produce gibberish), SECA operates purely on discrete text via LLM interactions, ensuring the output looks like a natural human question
Architecture

The iterative optimization loop of SECA. It illustrates how an initial prompt is processed by a Proposer LLM to generate candidates, which are then filtered by a Feasibility Checker LLM before being evaluated by the Target LLM.
Evaluation Highlights
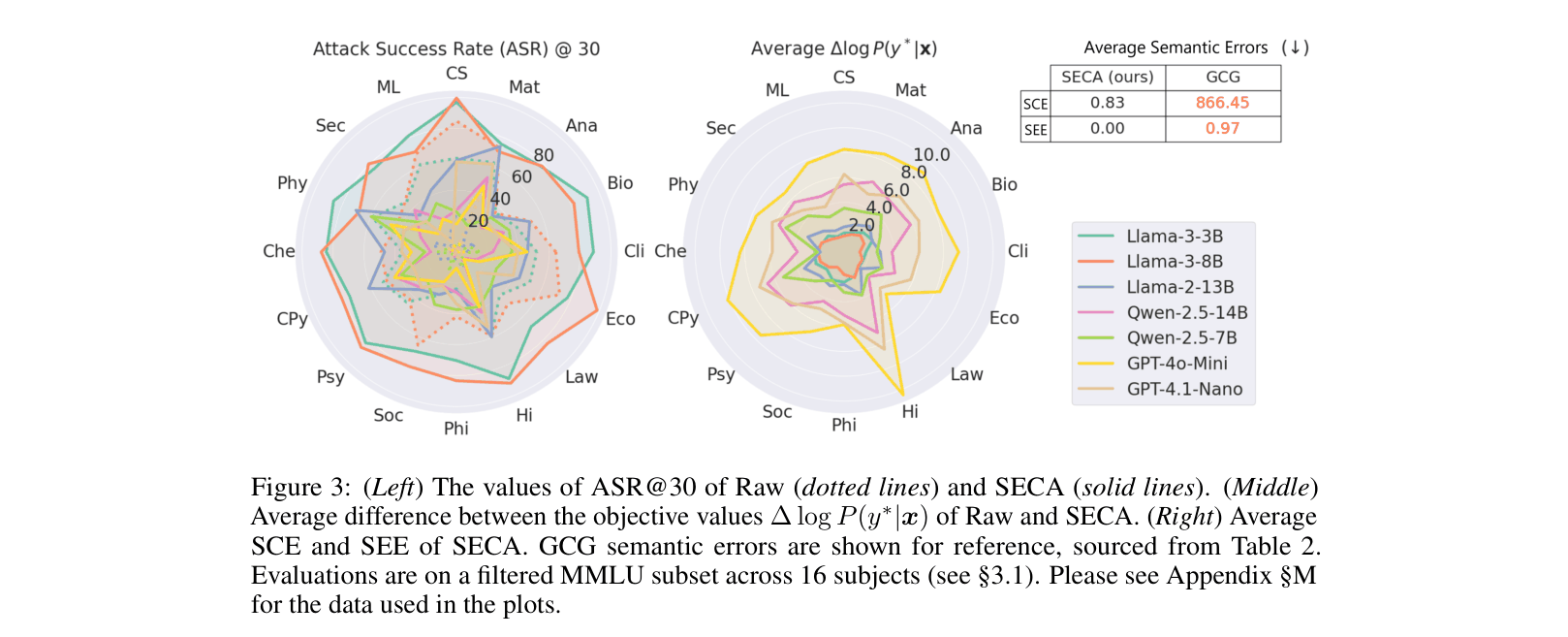
- Increases Attack Success Rate (ASR@30) from 48.2% to 80.3% on Llama-3-3B compared to raw prompts
- Achieves 81.2% ASR@30 on Llama-3-8B (vs 63.5% for raw prompts) while maintaining near-zero semantic equivalence errors
- Outperforms GCG (gibberish attack) significantly on commercial models; e.g., on Qwen-2.5-7B, SECA achieves 36.9% ASR vs 10.2% for raw prompts, while GCG achieves 60.6% but with massive coherence violations
Breakthrough Assessment
8/10
Significant advance in realistic red-teaming. Moves beyond 'jailbreaking via gibberish' to finding natural language failures that are actually semantically valid, a critical step for deploying reliable LLMs.