📝 Paper Summary
Hallucination suppression
Internal state analysis
LapEigvals detects hallucinations by treating LLM attention maps as graph adjacency matrices and using the top eigenvalues of their Laplacian as input features for a detection probe.
Core Problem
LLMs frequently generate hallucinations (nonsensical or unfaithful content) in safety-critical applications, and existing detection methods often fail to capture the subtle internal signals indicating these errors.
Why it matters:
- Eliminating hallucinations entirely is currently impossible, making reliable post-hoc detection essential for safe deployment
- Previous attention-based detection methods (like AttentionScore) often lack robustness or statistical separability between hallucinated and correct answers
- Understanding internal model states during hallucinations can offer insights into the mechanisms of model failure
Concrete Example:
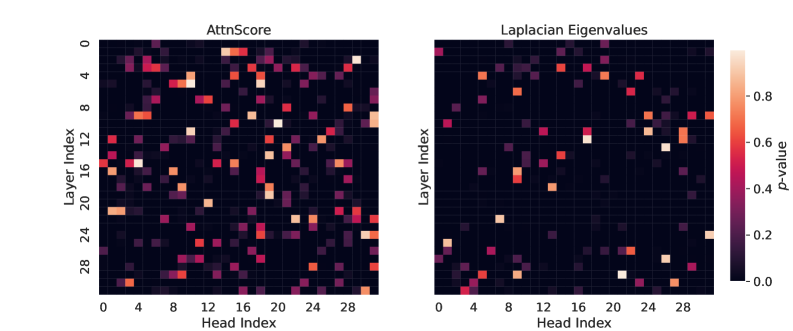
In TriviaQA, an LLM might answer a question incorrectly. Previous methods like AttentionScore (sum of log-determinants) often yield overlapping distributions for correct vs. incorrect answers (high p-values). LapEigvals shows significantly lower p-values, indicating distinct spectral signatures when the model hallucinates.
Key Novelty
LapEigvals (Laplacian Eigenvalues for Hallucination Detection)
- Interprets the attention mechanism as a directed graph where tokens are nodes and attention scores are edge weights, representing information flow
- Constructs a Laplacian matrix from these attention maps to capture structural properties like information bottlenecks, which hypothesized to correlate with hallucinations
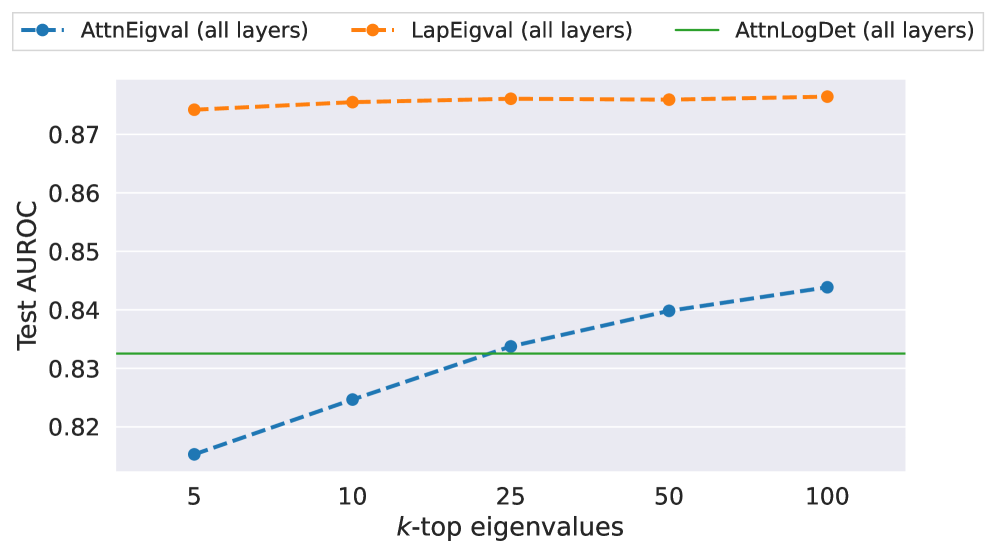
- Uses the top-k eigenvalues of this Laplacian matrix as a compact, informative feature vector for training a simple logistic regression probe
Architecture
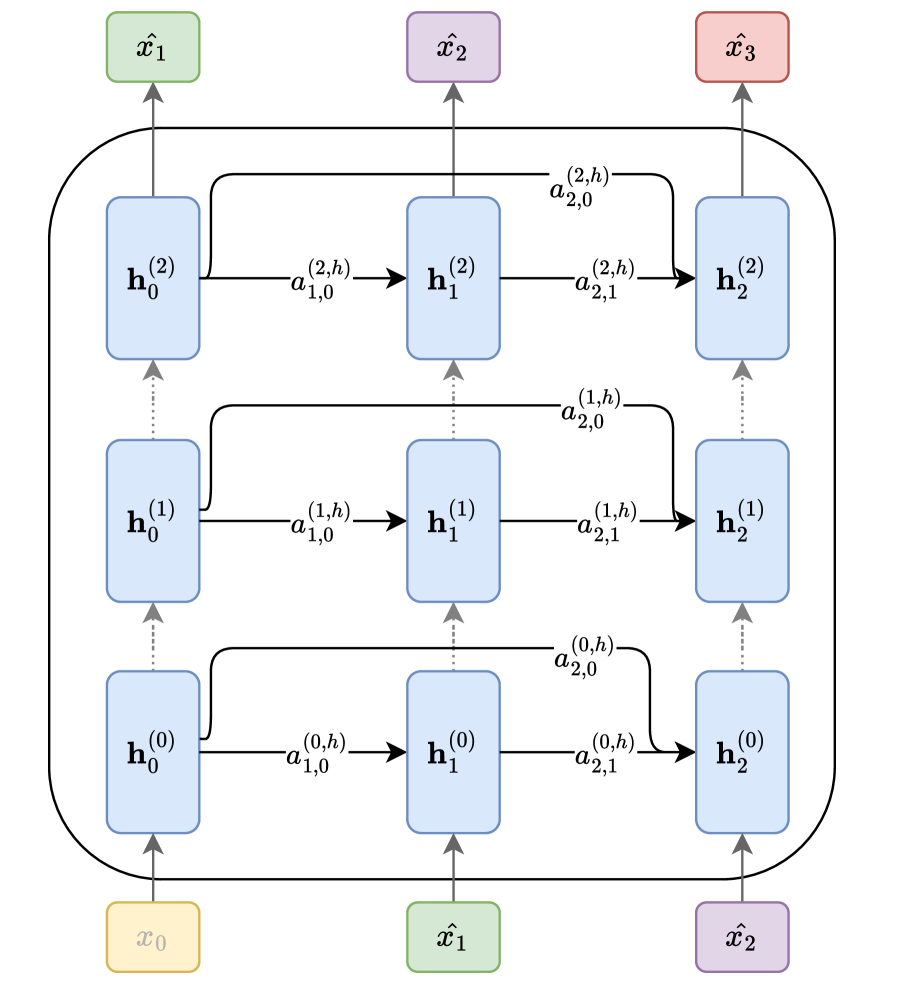
The pipeline for converting attention maps into Laplacian eigenvalues and training a probe. Figure 2 visualizes the graph interpretation of attention.
Evaluation Highlights
- Achieves state-of-the-art hallucination detection performance on 6 out of 7 QA datasets (including TriviaQA, CoQA, SQuADv2) across 5 LLM families
- Outperforms baseline AttentionScore and raw Attention Eigenvalues, with LapEigvals reaching ~0.82 AUROC on TriviaQA (Mistral-Small-24B) vs ~0.77 for best baseline
- Demonstrates robust generalization: training on one dataset (e.g., TriviaQA) and testing on another (e.g., NQ-Open) yields minimal performance drops compared to baselines
Breakthrough Assessment
7/10
Strong empirical results surpassing existing attention-based methods. The graph-theoretic interpretation of attention for hallucination detection is a novel and effective perspective, though it relies on a standard probing setup.