📊 Experiments & Results
Evaluation Setup
QA tasks where model generation is compared against ground truth; hallucination detection treated as binary classification (correct vs. incorrect).
Benchmarks:
- CoQA (Conversational Question Answering)
- TruthfulQA (Truthfulness benchmark)
- TriviaQA (Reading Comprehension / QA)
Metrics:
- AUROC (Area Under Receiver Operating Characteristic)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison results demonstrating INSIDE (EigenScore + Feature Clipping) performance against baselines on LLaMA-2-7B-Chat. | ||||
| CoQA | AUROC | 0.777 | 0.829 | +0.052 |
| TruthfulQA | AUROC | 0.781 | 0.816 | +0.035 |
| TriviaQA | AUROC | 0.788 | 0.806 | +0.018 |
| Ablation showing the specific contribution of Feature Clipping (FC) when added to the EigenScore metric. | ||||
| CoQA | AUROC | 0.800 | 0.829 | +0.029 |
| TruthfulQA | AUROC | 0.793 | 0.816 | +0.023 |
Experiment Figures
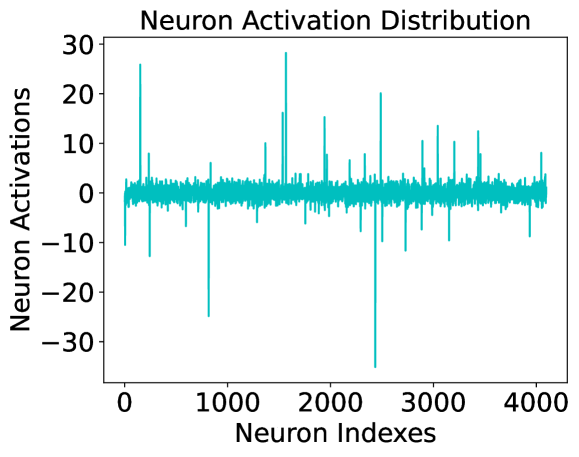
Activation distribution of the penultimate layer in LLaMA-7B.
Main Takeaways
- EigenScore consistently outperforms language-level consistency metrics (like Lexical Similarity) and logit-level metrics (Perplexity), validating the use of internal dense embeddings.
- Feature Clipping (FC) universally improves detection performance across benchmarks, confirming that truncating extreme activations helps mitigate overconfident hallucinations.
- The method generalizes across different model families (LLaMA-2 and Vicuna) and sizes (7B and 13B).
- Using the middle layer's last token embedding proves more effective for EigenScore than using the final layer, suggesting semantic information is best captured before the final output formatting.