📝 Paper Summary
Data Curation for LLM Pre-training
Synthetic Data Generation
ReWire recycles discarded low-quality web documents by using an LLM to rewrite them into high-quality training data via chain-of-thought reasoning, effectively doubling the usable data pool.
Core Problem
High-quality natural text data is scarce, and standard filtering pipelines discard up to 99% of web crawls, creating a 'data wall' that limits model scaling.
Why it matters:
- The stock of high-quality public human text is projected to be exhausted between 2026 and 2032
- Discarding 99% of data is inefficient when compute resources continue to grow
- Current synthetic data methods often focus on specific formats (Q&A) rather than general pre-training corpora
Concrete Example:
A web document might contain useful facts but be poorly written, incoherent, or unstructured (e.g., a messy product listing). Standard filters discard it. ReWire identifies the core purpose and rewrites it into a coherent document, making it usable for training.
Key Novelty
Recycling the Web with Guided Rewrite (ReWire)
- Instead of discarding low-quality documents, use a strong LLM (Llama-3.3-70B) to reason about their content and rewrite them into high-quality text
- Treats web scraps as 'initial drafts' rather than final training data, using the LLM to improve structure and coherence while retaining information
- Demonstrates that mixing this 'recycled' synthetic data with real high-quality data works better than using real data alone or simply repeating real data
Architecture
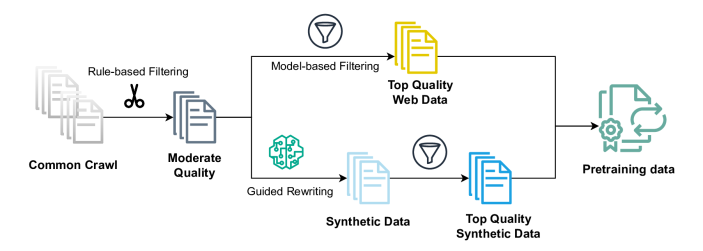
The overall data generation pipeline for ReWire
Evaluation Highlights
- +2.5 percentage points improvement on CORE average accuracy (22 tasks) at 7B scale when mixing recycled data with raw text vs. raw text alone
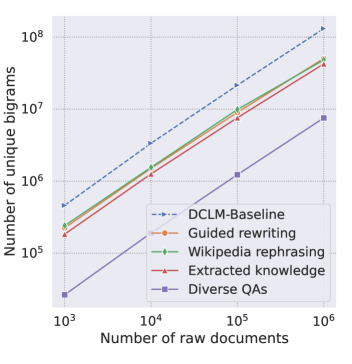
- Matches or outperforms the performance of training on 2x more raw data, effectively doubling the token yield
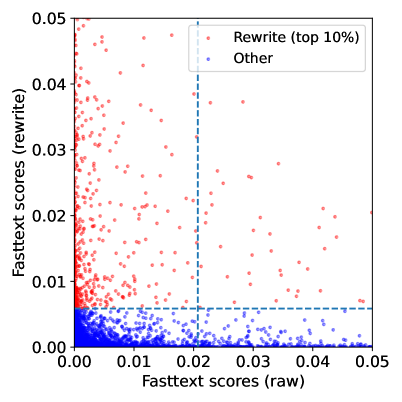
- 82% of the useful synthetic data comes from documents that would have been discarded by standard quality filters
Breakthrough Assessment
8/10
Offers a scalable solution to the impending 'data wall' by proving that 'trash' data can be recycled into high-quality training signal, effectively acting as a data multiplier.