📝 Paper Summary
Agentic AI
Hallucination detection
Reliability and safety
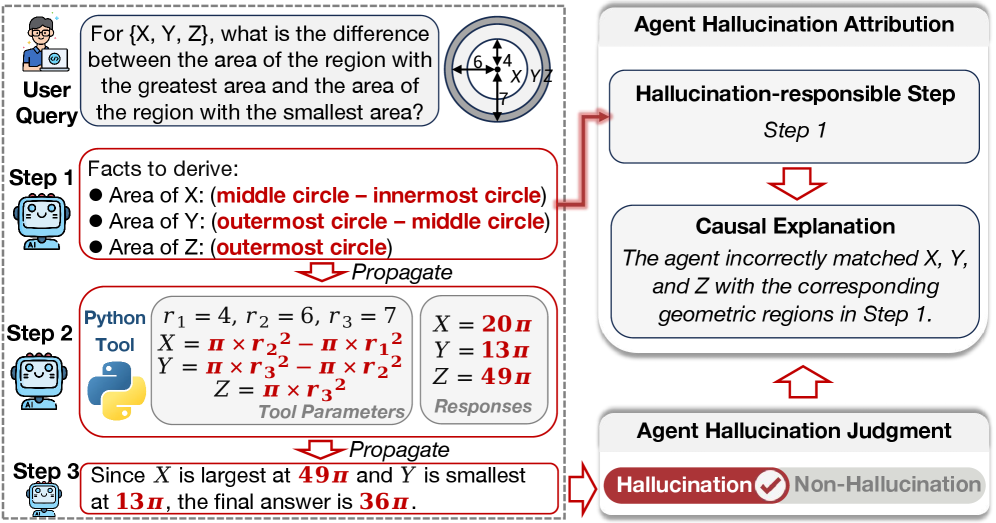
AgentHallu is a benchmark for identifying exactly where and why hallucinations occur in multi-step agent trajectories, revealing that even advanced models struggle to pinpoint error origins, especially in tool use.
Core Problem
Existing hallucination evaluations focus on binary judgments of single-turn responses, failing to identify which specific step in a multi-step agent workflow (planning, tool use, reasoning) causes the initial divergence.
Why it matters:
- Agentic hallucinations propagate: a small error in an early planning or tool parameter step can cascade, leading to incorrect final outcomes
- Current binary metrics cannot diagnose the root cause of failure in sequential workflows, which is essential for debugging and building reliable autonomous systems
- High-stakes applications require granular transparency to trust agent decisions, not just a final correct/incorrect label
Concrete Example:
A planning step misdefines 'region X, Y, Z', which propagates into downstream Python tool parameters, eventually leading to a wrong answer. A binary detector just flags the final answer as wrong, but AgentHallu identifies 'Step 1' as the root cause and explains the mismatch.
Key Novelty
Automated Hallucination Attribution for Agents
- Shifts focus from 'is this wrong?' (binary detection) to 'which step went wrong and why?' (step localization and causal explanation) in multi-step trajectories
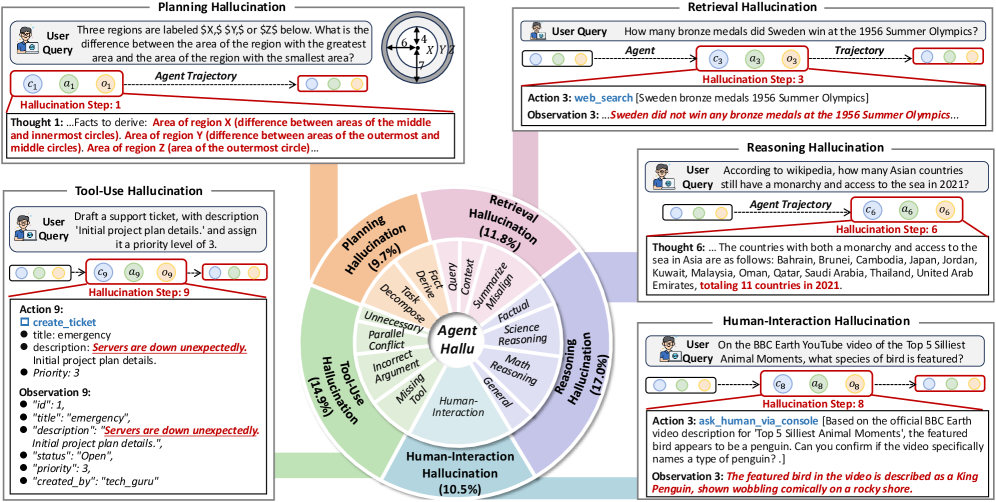
- Introduces a grounded taxonomy of agent hallucinations covering 5 categories (Planning, Retrieval, Reasoning, Human-Interaction, Tool-Use) derived from empirical analysis
- Provides a dataset of 693 trajectories from 7 agent frameworks with dense annotations including the specific responsible step and natural language explanation
Architecture
The dataset construction pipeline for AgentHallu.
Evaluation Highlights
- Gemini-2.5-Pro (best model) achieves only 41.1% accuracy in localizing the hallucination-responsible step
- Performance drops significantly on tool-use hallucinations, with the best model achieving just 11.6% localization accuracy
- Longer trajectories degrade performance: GPT-5 accuracy drops from 40.3% on short sequences (≤5 steps) to 23.9% on long sequences (≥11 steps)
Breakthrough Assessment
8/10
Establishes a critical new task (attribution) for the growing field of agents. The low performance of SOTA models (GPT-5/Gemini-2.5) demonstrates this is a non-trivial, unsolved problem essential for future reliability.