📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Chain-of-Thought Reasoning
Post-training pipelines
RLMT extends the success of reinforcement learning with reasoning traces beyond math/code to general open-ended chat by optimizing long chain-of-thought generation against a standard preference-based reward model.
Core Problem
Current reasoning models trained via RL with verifiable rewards (RLVR) excel at math and code but generalize poorly to open-ended tasks like creative writing or general chat.
Why it matters:
- Humans routinely use planning and reasoning for everyday open-ended tasks (e.g., writing essays, planning meals), not just math puzzles
- Math-focused reasoning models (like DeepSeek-R1-Zero) lag behind standard instruct models on general chat benchmarks
- Skills acquired from verifiable domains (math/code) do not naturally transfer to general reasoning tasks
Concrete Example:
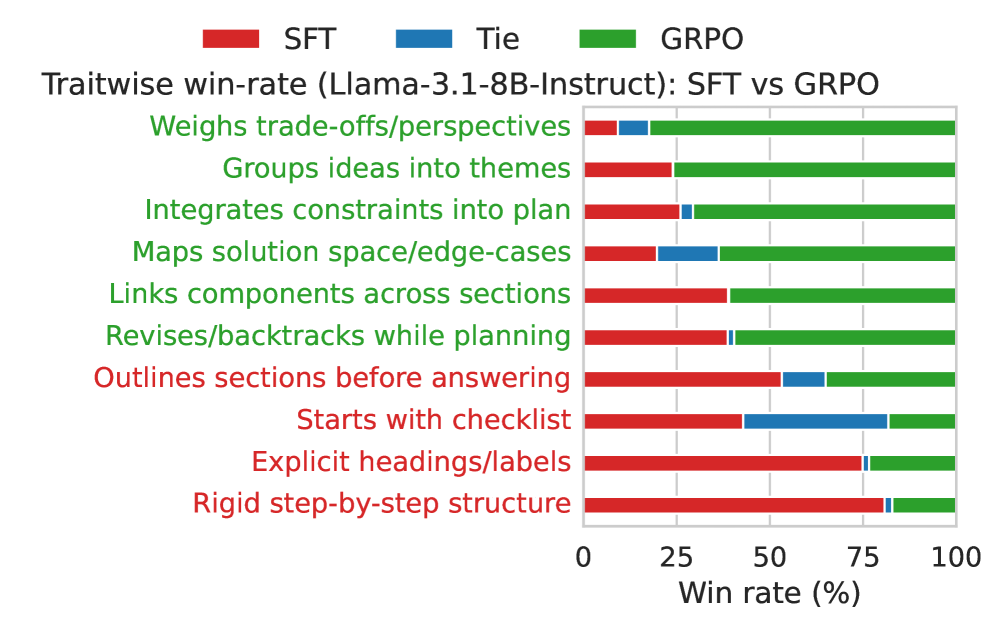
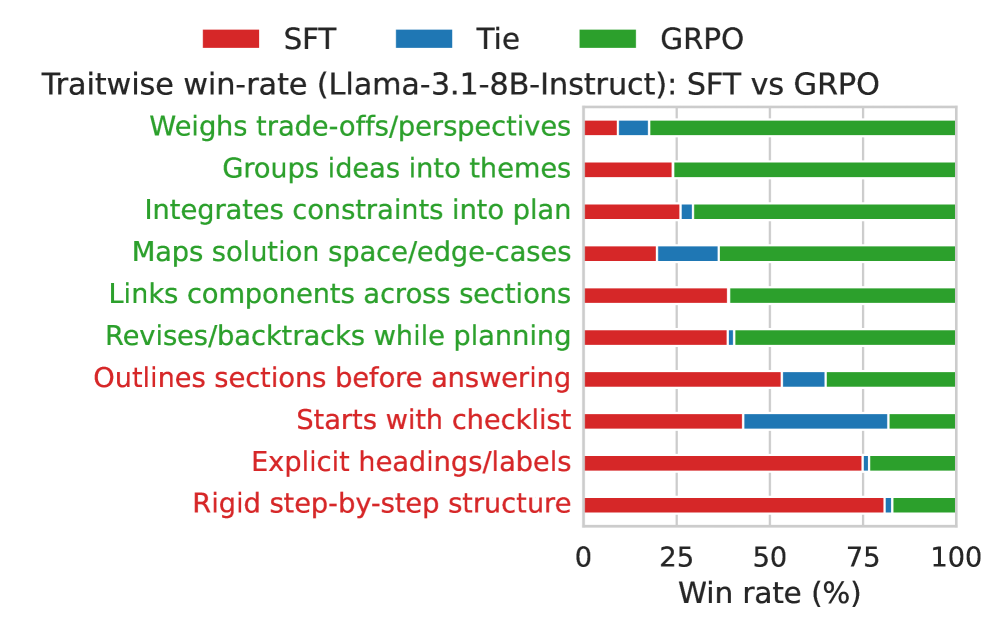
When asked to write a travel blog post, a math-optimized reasoning model might fail to structure the narrative engagingly or hallucinate rigid constraints, whereas RLMT plans themes and constraints explicitly before writing, resulting in a richer output.
Key Novelty
Reinforcement Learning with Model-rewarded Thinking (RLMT)
- Applies the 'thinking' paradigm (generating long CoT before answering) to general chat domains where ground-truth verification is impossible
- Replaces the rule-based verifiers of RLVR with a learned preference reward model (like in RLHF) to score the final response
- Demonstrates that reasoning capabilities can be elicited in base models without supervised fine-tuning (SFT) or with SFT warm-starts using only 7K prompts
Architecture

Conceptual comparison between Standard RLHF, RLVR, and the proposed RLMT pipeline.
Evaluation Highlights
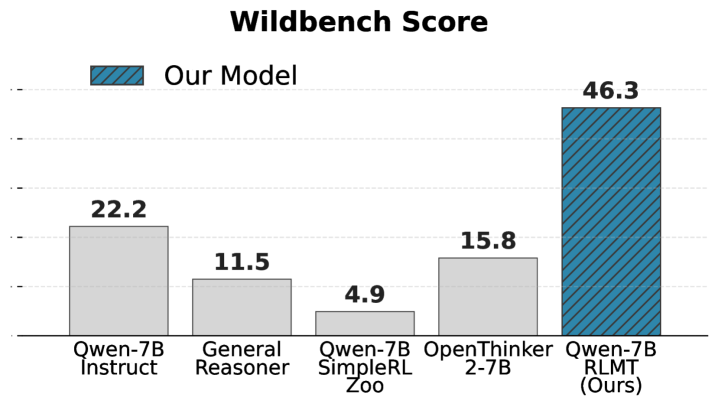
- +3 to +7 points on chat benchmarks (AlpacaEval2, WildBench, ArenaHardV2) compared to standard RLHF baselines
- Llama-3.1-8B trained with RLMT outperforms GPT-4o and rivals Claude-3.7-Sonnet (Thinking) on WildBench and creative writing tasks
- Base Llama-3.1-8B with 'Zero' RLMT (no SFT) outperforms the official Llama-3.1-8B-Instruct model (tuned on 25M+ examples) by >5 points on chat benchmarks
Breakthrough Assessment
9/10
Successfully bridges the gap between 'reasoning' models (usually restricted to math/code) and general chat, showing that long CoT improves open-ended generation significantly even with small data and models.