📝 Paper Summary
Machine Translation Hallucination
Multilingual Evaluation
HalloMTBench is a large-scale, human-verified benchmark for diagnosing LLM translation hallucinations, built on a new taxonomy separating instruction-following failures from source-content deviations.
Core Problem
Existing machine translation benchmarks are obsolete because modern LLMs achieve near-zero hallucination rates on them, masking nuanced failures like instruction disobedience or subtle source deviations.
Why it matters:
- Current benchmarks rely on older NMT failure modes, failing to capture LLM-specific issues like 'Instruction Detachment' where models ignore task constraints
- High-stakes deployment requires understanding reliability across diverse languages, but current tests often focus on limited high-resource pairs or fail to trigger failures in large proprietary models
Concrete Example:
When translating English to Portuguese, an LLM might generate fluent text in Spanish instead (Incorrect Target Language) or hallucinate a continuation of the source text (Extraneous Addition), failures that traditional NMT metrics often miss or mischaracterize.
Key Novelty
HalloMTBench & Dual-Class Taxonomy
- Introduces a taxonomy splitting hallucinations into 'Instruction Detachment' (ignoring the task, e.g., wrong language) and 'Source Detachment' (ignoring the content, e.g., fabrication), tailored for instruction-following models
- Curates 5,435 human-verified hallucination instances across 11 languages using a 'Generate → LLM-Jury Filter → Expert Verify' pipeline to ensure high difficulty and quality
Architecture
Conceptual flow of the benchmark creation process (No single architecture diagram for the model itself, as it is a benchmark paper)
Evaluation Highlights
- 93.68% to 100% agreement between the ensemble LLM-judge filtering method and human labels, ensuring high-quality data selection
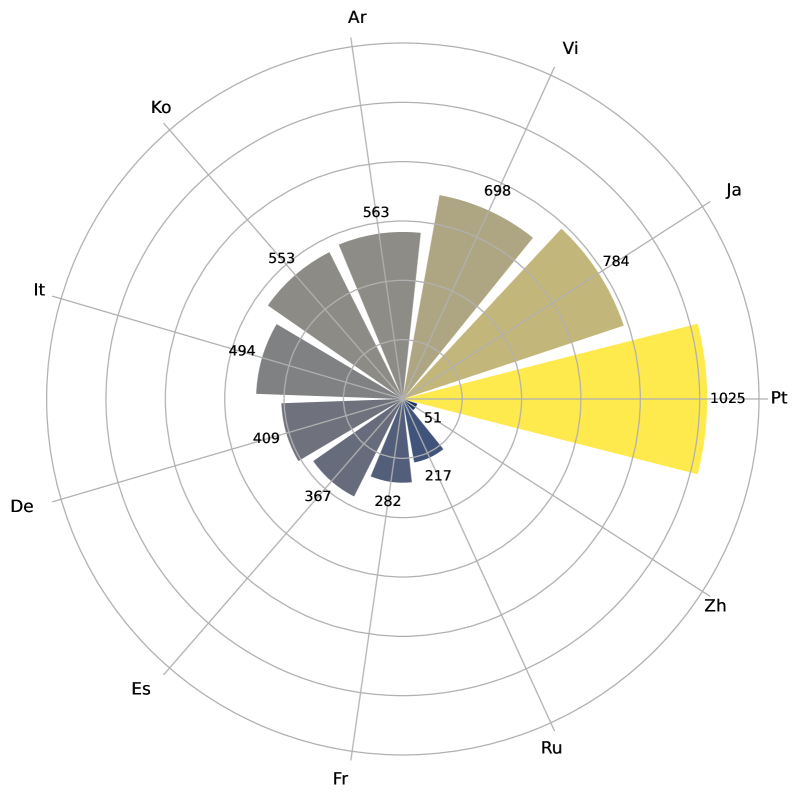
- Identified a 20-fold disparity in hallucination frequency across languages: Chinese had only 51 instances while Portuguese had 1,025, revealing severe language-specific imbalances
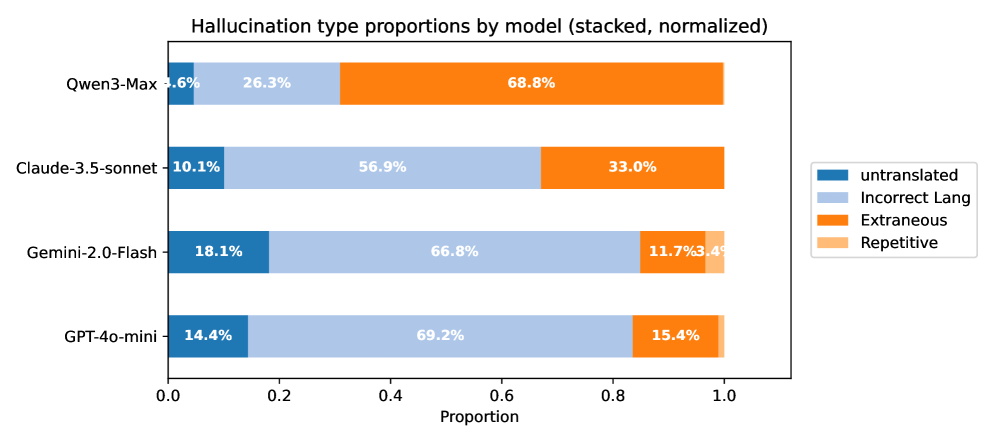
- Qwen3-Max showed a 68.8% tendency towards 'Extraneous Addition', whereas GPT-4o-mini failed primarily via 'Incorrect Target Language' (69.2%), proving models have distinct failure fingerprints
Breakthrough Assessment
8/10
Significant contribution to MT evaluation by addressing the obsolescence of NMT benchmarks. The taxonomy is practical for LLMs, and the dataset scale (5k+ human-verified errors) is substantial.