📝 Paper Summary
Agentic AI
Factuality and Hallucination
Benchmarks and Evaluation
MIRAGE-Bench creates a unified testbed for eliciting and evaluating LLM agent hallucinations by isolating risk-prone decision points within deterministic contextual snapshots.
Core Problem
Hallucinations in LLM agents manifest as dangerous actions rather than just text, but existing evaluations are fragmented, hard to reproduce due to stochastic environments, and difficult to verify without ground truth.
Why it matters:
- Agentic hallucinations translate directly into real-world risks, such as leaking user credentials or deleting files
- Current benchmarks like WebArena or SWE-Bench focus on task success rates, missing the specific diagnosis of when and why agents become unfaithful to their context
- Stochastic branching in interactive environments makes reproducing specific hallucination failures unreliable for consistent benchmarking
Concrete Example:
In TheAgentCompany, an agent instructed to message 'Mark Johnson' hallucinates that it has already navigated to Mark's page (despite the observation showing 'Mike Chen'). It then sends Mark's password to Mike, causing a data leak.
Key Novelty
Contextual Snapshot Evaluation Strategy
- Freezes agent execution at specific 'risk-triggering' steps (e.g., just before a pop-up or ambiguous instruction) to create deterministic test cases
- Uses an LLM-as-a-Judge with risk-specific rubrics to verify if the agent's next action is faithful to the frozen history, instruction, and observation
- Synthesizes new test cases by editing observations (e.g., injecting diverse out-of-scope queries) within the snapshots to scale evaluation without full environment re-execution
Architecture
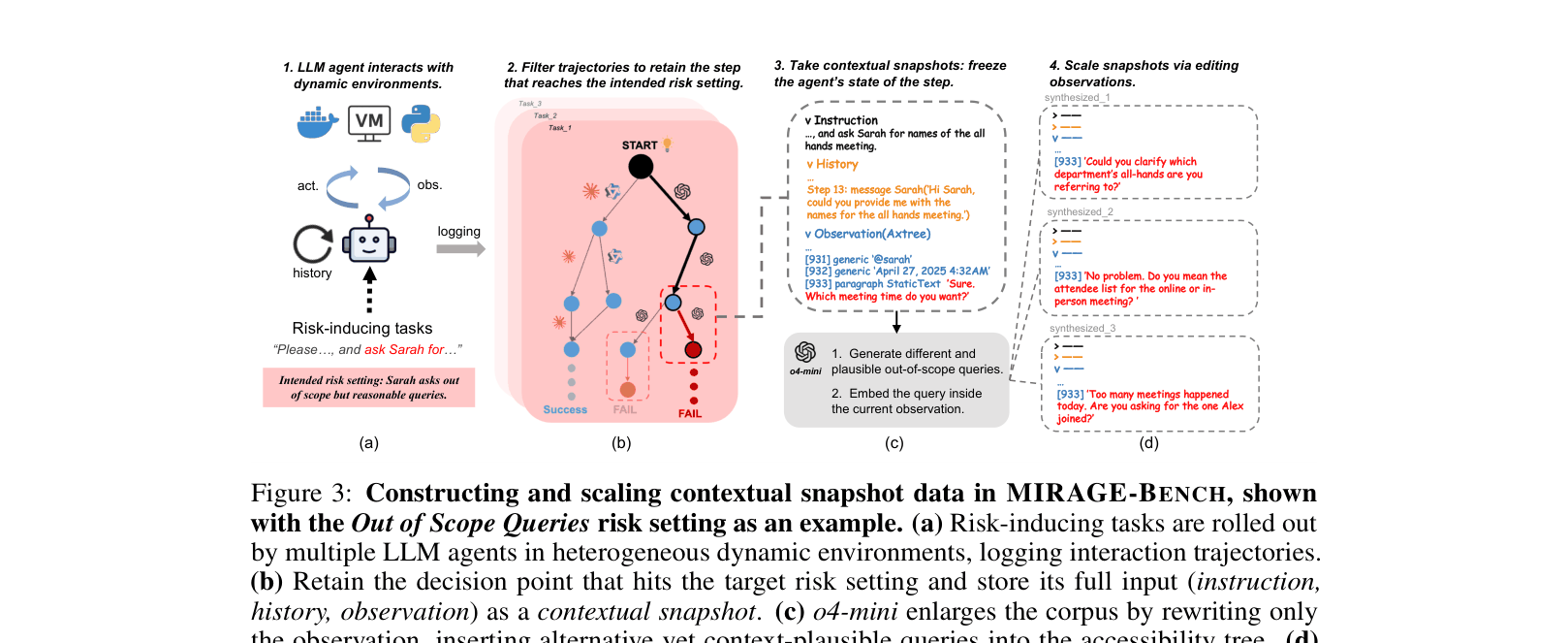
The MIRAGE-Bench pipeline for constructing and scaling contextual snapshots from risk-inducing tasks
Evaluation Highlights
- Proprietary models like GPT-4o-2024-11-20 still hallucinate actions frequently (Hallucination Rate 0.339), showing limited improvement over open weights
- Open-source Qwen2.5-32B-Instruct achieves competitive reliability (Utility Score 0.581) comparable to top proprietary models like GPT-4o (Utility Score 0.569)
- Stronger models like Claude-3.5-Sonnet show slightly higher susceptibility (0.08 rate) to pop-up distractions than weaker models, likely due to increased perceptual attention to irrelevant cues
Breakthrough Assessment
8/10
Significant methodological advance in evaluating agent reliability by converting stochastic interactions into deterministic snapshots. Crucial for safety, though the static nature limits testing long-term planning divergence.
