📝 Paper Summary
Hallucination detection
Internal representation analysis
Uncertainty quantification
HaMI reformulates hallucination detection as a multiple instance learning problem to adaptively identify critical hallucinated tokens within free-form generations, augmenting them with uncertainty metrics for robust detection.
Core Problem
Existing hallucination detectors rely on predetermined tokens (e.g., last token) for analysis, which fails in free-form generation where hallucinated content is sparsely distributed and varies in position.
Why it matters:
- Predetermined token selection (e.g., last token) overlooks the actual location of hallucinated entities, leading to poor detection accuracy in variable-length responses
- Hallucinations pose safety risks in high-stakes fields like law and medicine, requiring reliable detection before deployment
- Current methods often require expensive external LLMs or multiple sampling steps, increasing computational cost
Concrete Example:
In a long response about a historical event, the hallucinated date might appear in the middle of the text. A detector analyzing only the 'last token's' internal state would miss this signal, whereas the hallucination is actually encoded in the specific token representing the incorrect date.
Key Novelty
Hallucination detection as Multiple Instance Learning (HaMI)
- Treats each response sequence as a 'bag' of token instances, where a hallucinated response is a 'positive bag' containing at least a few hallucinated tokens
- Optimizes a detector to assign high scores to the specific tokens most indicative of hallucination, rather than averaging or picking fixed positions
- Augments standard internal hidden states with uncertainty metrics (like predictive probability or semantic entropy) directly in the feature space
Architecture
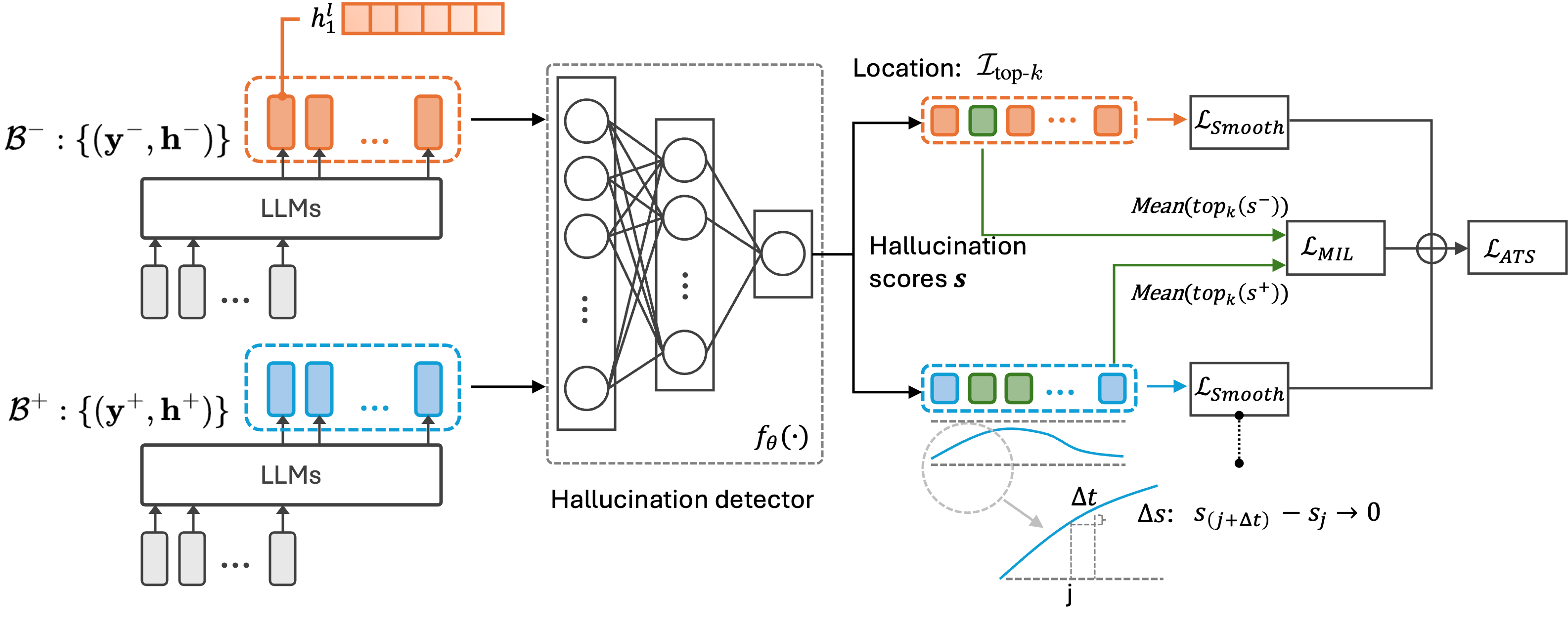
The overall framework of HaMI, illustrating the process from token generation to score prediction and loss calculation.
Evaluation Highlights
- Significantly outperforms state-of-the-art methods like SAPLMA and HaloScope across four benchmarks (TriviaQA, SQuAD, NQ, BioASQ)
- Achieves 8.1% to 11.9% average AUROC improvement over MARS-SE (a strong uncertainty-based baseline) on three different LLMs
- Demonstrates robustness across different model families (LLaMA-3, Mistral) and sizes (8B to 70B)
Breakthrough Assessment
8/10
Novel formulation of hallucination detection as MIL addresses the critical flaw of fixed-token analysis. Strong empirical results across diverse datasets and models confirm its effectiveness over existing baselines.
