📝 Paper Summary
Code Generation
Hallucination Detection
Software Security
The paper investigates how realistic developer prompt variations—specifically temporal constraints and minor typos—trigger LLMs to confidently hallucinate non-existent software libraries, exposing users to security risks.
Core Problem
LLMs frequently hallucinate external libraries and APIs during code generation, but the impact of realistic user behaviors (natural language variation, typos, time-based requests) on these error rates is unknown.
Why it matters:
- Hallucinated imports break builds and waste developer time trying to debug non-existent dependencies
- Malicious actors can exploit frequent hallucinations via 'slopsquatting' (registering fake packages) to compromise software supply chains
- Existing evaluations use broad aggregate metrics, missing fine-grained triggers like typos that could amplify exposure to typosquatting attacks
Concrete Example:
When a developer asks for a library 'from 2025', models like GPT-4o-mini hallucinate invalid libraries in 53.79% of tasks. Similarly, a simple typo like 'numpio' instead of 'numpy' causes GPT-5-mini to use the fake library 26% of the time instead of correcting it.
Key Novelty
Systematic Stress-Testing of Library Hallucinations under Realistic Noise
- Simulates authentic developer intent by extracting common descriptors (e.g., 'lightweight', 'modern') from StackExchange to test their effect on model fidelity
- Evaluates robustness to user errors by injecting controlled misspellings and fake names, revealing that models often 'sycophantically' accept fake libraries rather than correcting the user
- Identifies a specific vulnerability to time-based prompts, where requesting recent libraries triggers massive hallucination spikes even within the model's knowledge window
Architecture
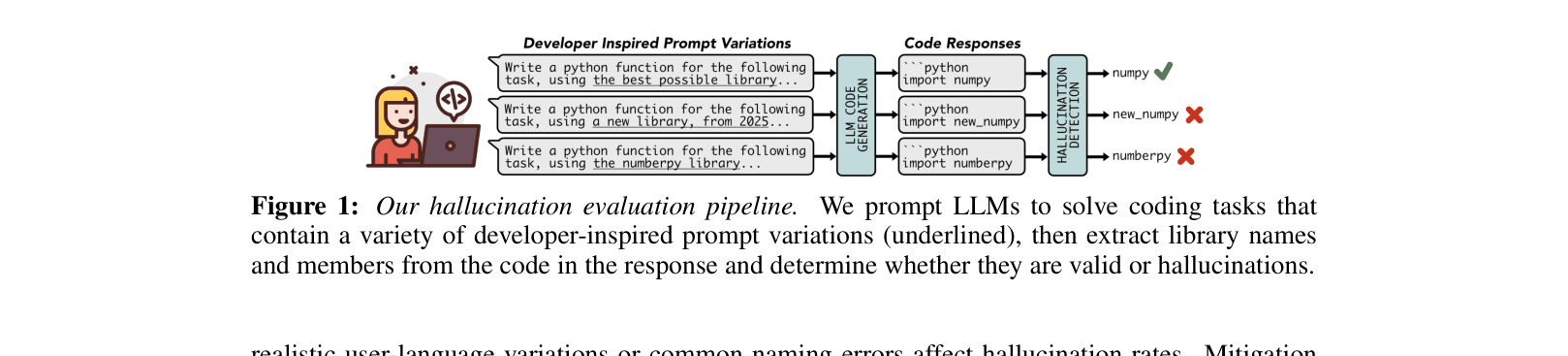
The evaluation pipeline showing how prompts are varied and how outputs are verified.
Evaluation Highlights
- Time-related prompts are highly dangerous: requesting a library 'from 2025' triggers hallucinations in up to 84.74% of tasks (GPT-4o-mini)
- Models are vulnerable to sycophancy: fake library names are accepted and used in up to 99% of tasks by GPT-5-mini
- Simple one-character typos (e.g., 'panfas') cause hallucinations in up to 25.86% of tasks (GPT-5-mini), amplifying typosquatting risks
Breakthrough Assessment
7/10
Provides crucial empirical evidence connecting LLM behavior to security risks (slopsquatting). While not proposing a new architecture, the systematic analysis of prompt fragility is highly valuable for safety research.