📊 Experiments & Results
Evaluation Setup
Generation of code for specific tasks across 3 languages (Python, JS, Rust), checked against package registries
Benchmarks:
- Custom Package Hallucination Test (Code Generation & Dependency Verification) [New]
- HumanEval (Python Code Generation)
- MBPP (Python Code Generation)
Metrics:
- Package Hallucination Rate (PHR)
- Statistical methodology: Pearson correlation coefficient (ρ) and p-values reported for correlations between model size/benchmarks and PHR. T-test used for coding vs. general-purpose model comparison.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Results showing PHR variations across different programming languages. | ||||
| Custom Package Hallucination Test | Mean PHR (Python) | 13.63 | 46.15 | +32.52 |
| Custom Package Hallucination Test | Mean PHR (Rust) | Not reported in the paper | 24.74 | Not reported in the paper |
| Results correlating model characteristics (size, benchmark performance) with hallucination rates. | ||||
| HumanEval vs PHR | Pearson Correlation (ρ) | 0 | -0.7887 | -0.7887 |
| Model Size vs PHR | Pearson Correlation (ρ) | 0 | -0.542 | -0.542 |
| Custom Package Hallucination Test | PHR (Nemotron-Llama-3.1-70B) | 24.40 | 0.22 | -24.18 |
Experiment Figures
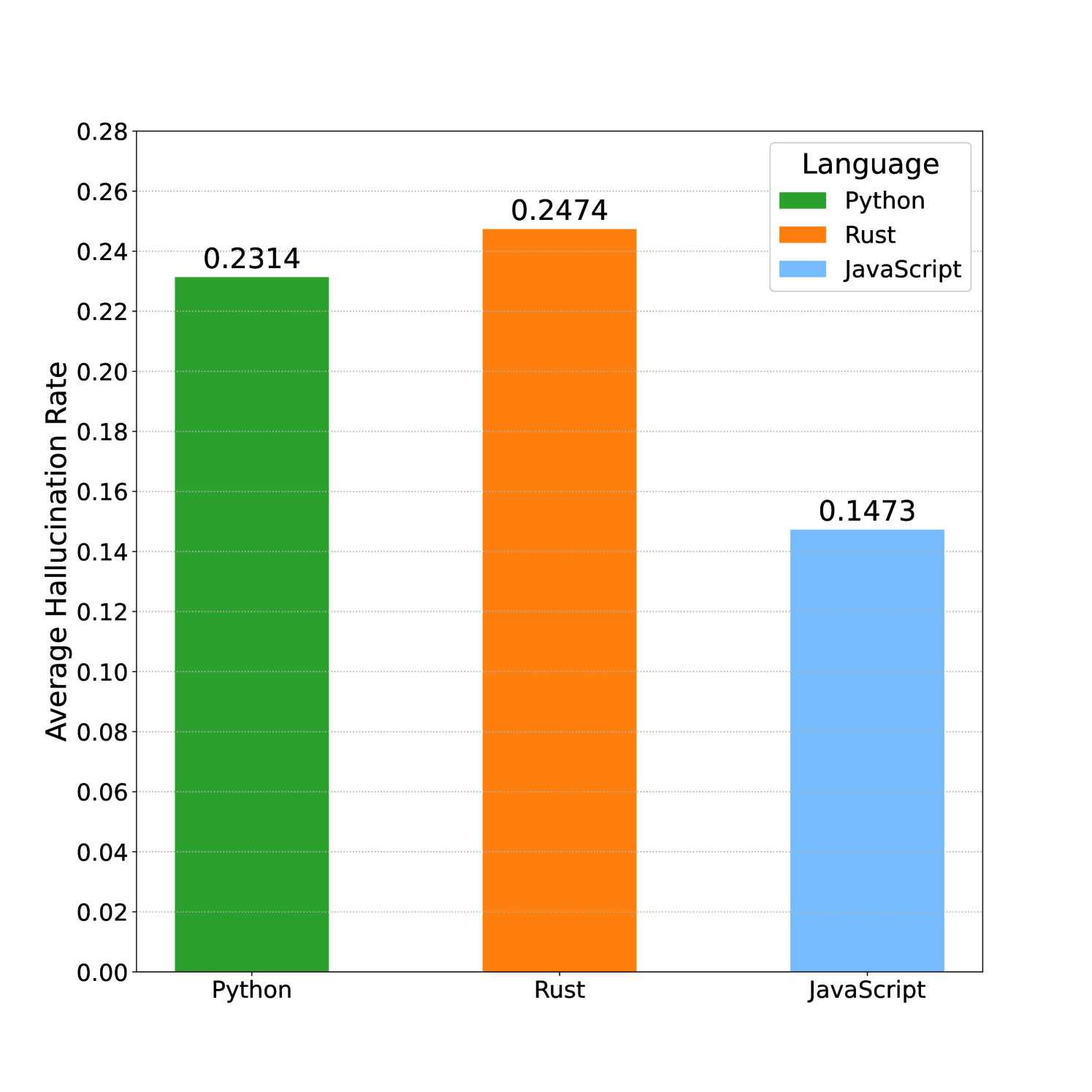
Box and whisker plot of Package Hallucination Rate (PHR) by programming language.
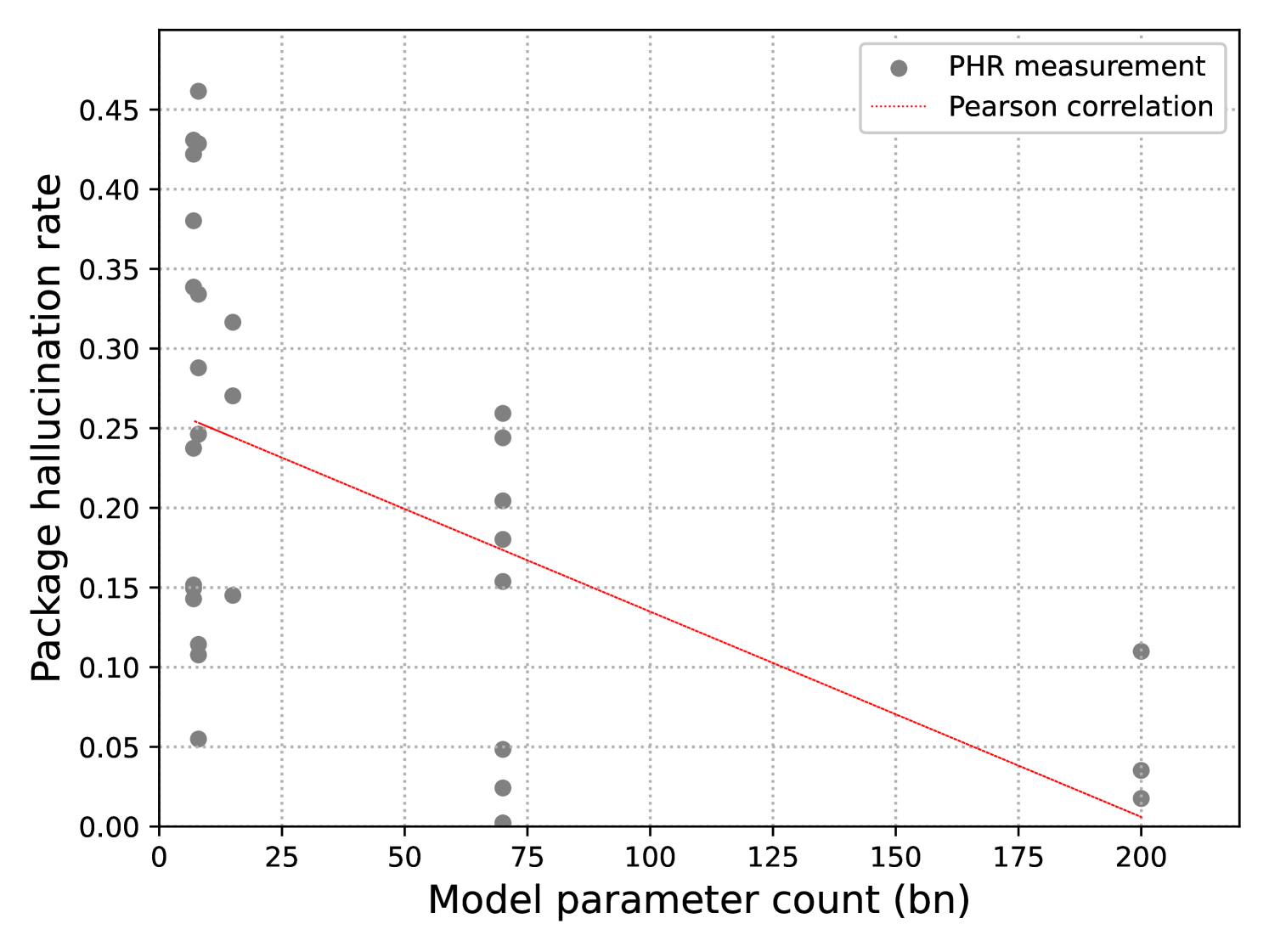
Scatter plot of Model Size (log scale) vs Package Hallucination Rate.
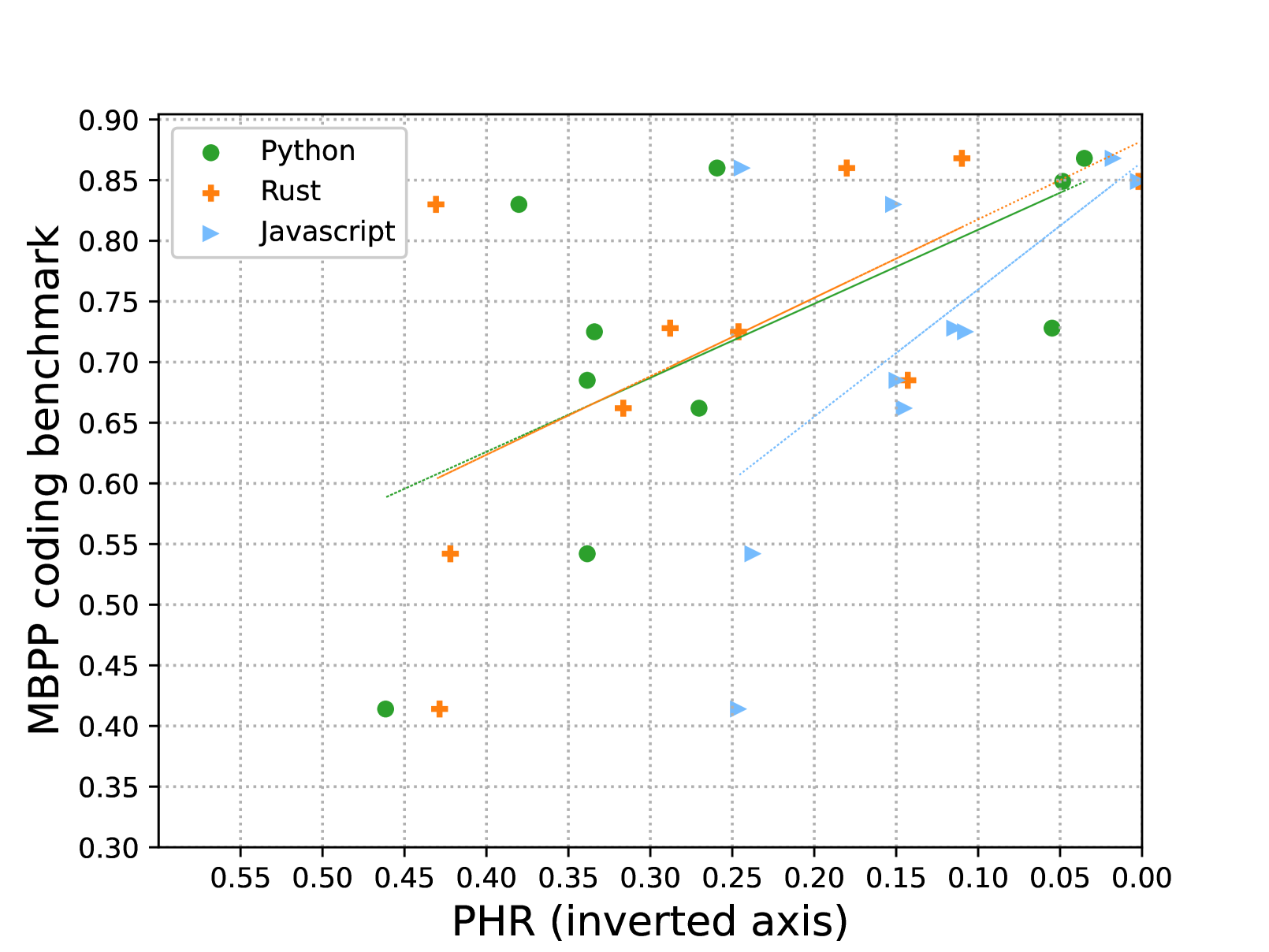
Scatter plot of HumanEval Score vs Package Hallucination Rate.
Main Takeaways
- All models tested were vulnerable to package hallucination across all languages, though larger models (>70B) are significantly more resistant
- JavaScript prompts result in fewer hallucinations than Python or Rust, likely due to the massive size of the NPM ecosystem (3.4M packages) reducing the space of unregistered names
- There is no statistically significant difference in hallucination rates between specialized 'coding' models and general-purpose models (after removing outliers like GPT-4o)
- Coding benchmark scores (specifically HumanEval) serve as a strong proxy for package security; if a model scores well on HumanEval, it likely has a lower Package Hallucination Rate