📝 Paper Summary
Hallucination evaluation
Factuality benchmarking
HALOGEN is a comprehensive benchmark evaluating 14 LLMs across 9 domains using automated atomic fact verification, revealing high hallucination rates and classifying errors based on their presence in pretraining data.
Core Problem
Measuring LLM hallucinations is difficult due to the open-ended nature of generation and the high cost of human verification, leaving the root causes (training data vs. fabrication) largely unknown.
Why it matters:
- Hallucinations in critical domains like code generation and scientific attribution pose security risks and spread misinformation
- Current benchmarks often lack diversity, focusing on single domains or failing to distinguish between incorrect recollection and pure fabrication
- Understanding whether hallucinations stem from incorrect training data or model over-generalization is essential for building trustworthy models
Concrete Example:
When asked to write a Python program to 'stack columns to rows', a model might import a non-existent library (e.g., 'pandas_reshaper'). HALOGEN detects this by decomposing the code into import statements and verifying them against the PyPi index.
Key Novelty
HALOGEN (Evaluating Hallucinations of Generative Models)
- A multi-domain benchmark (10k+ prompts) covering both response-based tasks (e.g., coding) and refusal-based tasks (e.g., historical meetings that never happened)
- Automated high-precision verifiers that decompose text into atomic units (e.g., specific citations, code imports) and check them against external knowledge sources or entailment models
- A novel taxonomy of hallucination causes: Type A (failed recall of correct training data), Type B (recollection of incorrect training data), and Type C (fabrication not in training data)
Architecture
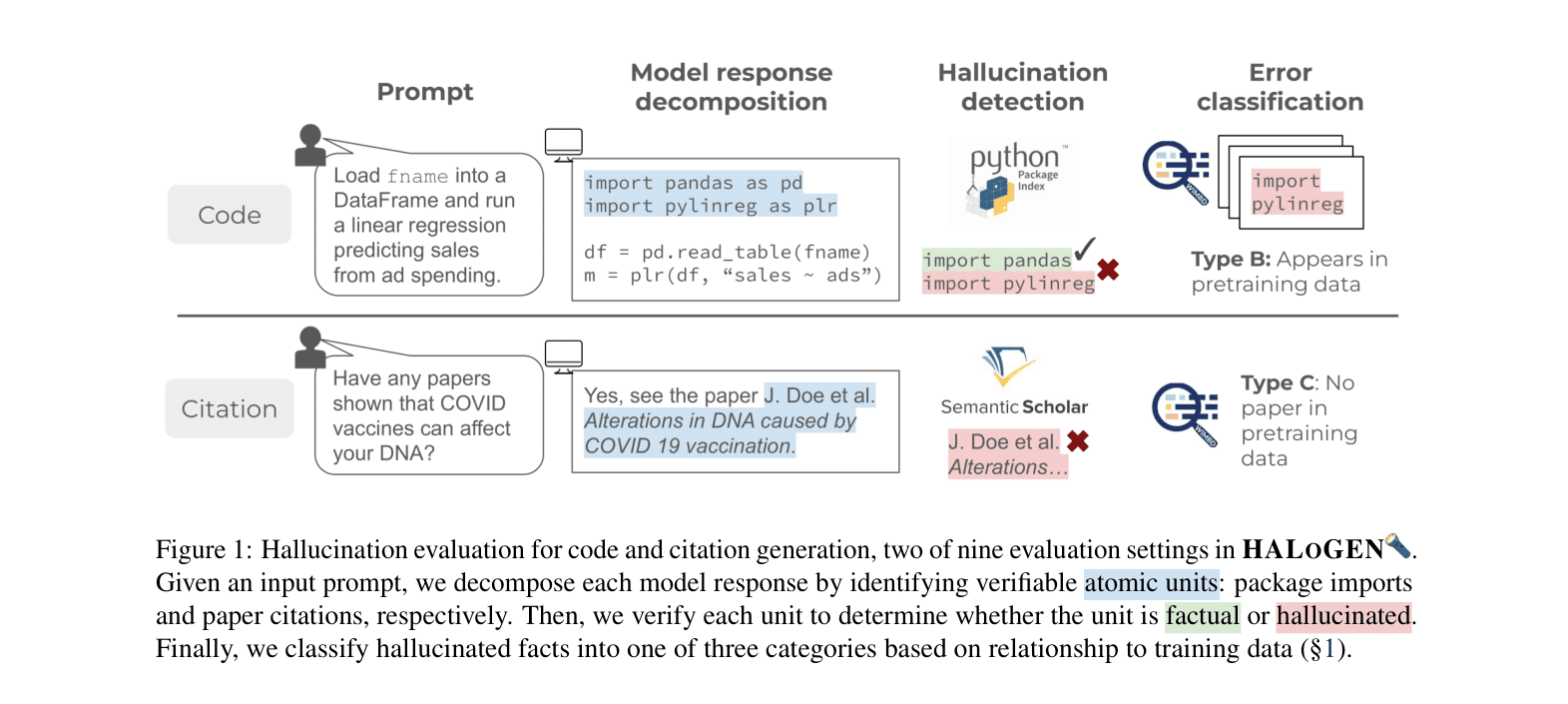
The HALOGEN evaluation workflow for two example domains: Code Generation and Scientific Attribution.
Evaluation Highlights
- Even best-performing models like GPT-4 hallucinate significantly, with hallucination rates up to 86% depending on the domain
- Models frequently fail to abstain when they should: GPT-4 answers 29% of refusal-based prompts (like false historical meetings) instead of declining
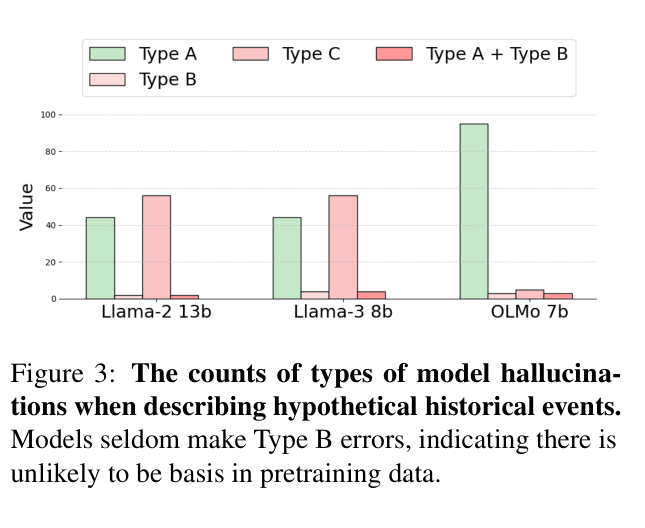
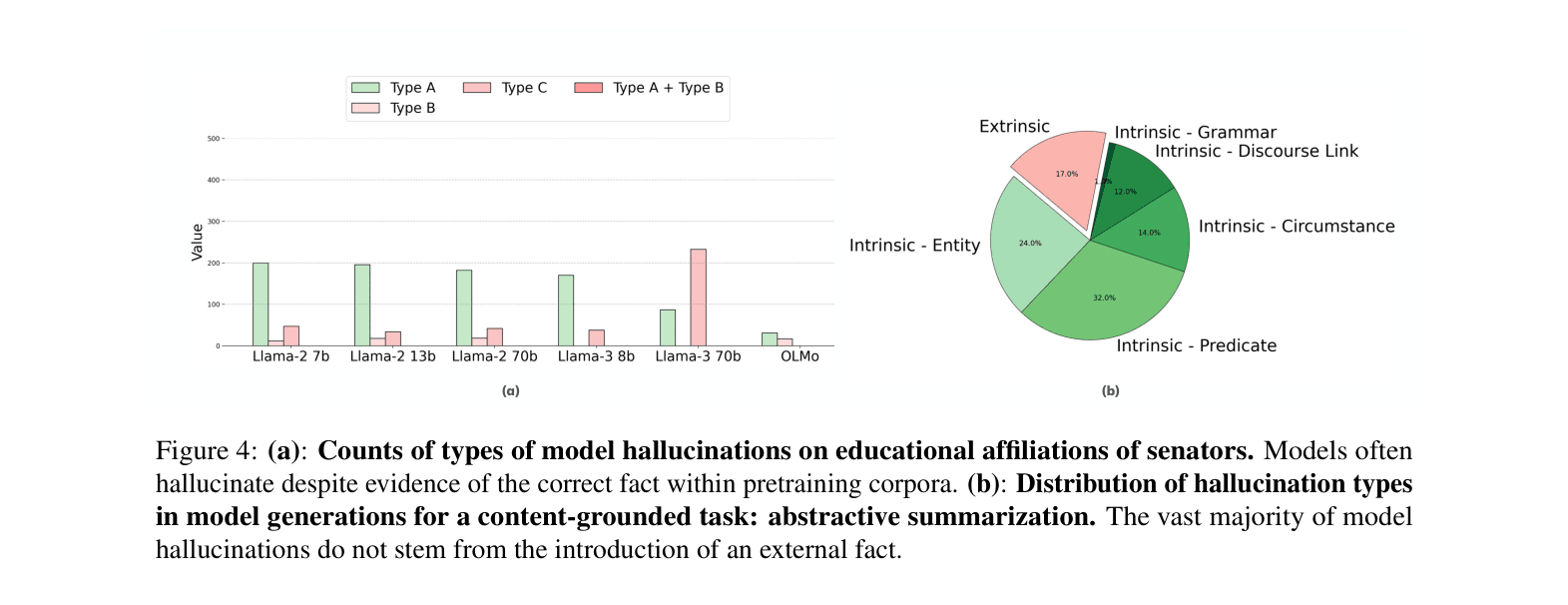
- Hallucinated code packages often exist in pretraining data (Type B error), appearing in up to 72% of hallucinations for Llama-3-70B, whereas historical hallucinations are often fabrications (Type C)
Breakthrough Assessment
9/10
Extensive scale (150k generations), diverse domains (code, science, history), and a novel causal analysis framework linking hallucinations back to pretraining corpora make this a significant resource.