📝 Paper Summary
Hallucination suppression
Uncertainty estimation
Consortium Consistency extends self-consistency and semantic entropy by aggregating responses from multiple heterogeneous LLMs, improving hallucination detection and mitigation compared to single-model approaches.
Core Problem
Single-model consistency methods fail when a model consistently hallucinates the same incorrect answer (imperfect calibration) or when its internal uncertainty measures are misleadingly low.
Why it matters:
- Hallucinations are a major barrier to LLM deployment, especially when models make 'educated guesses' due to instruction fine-tuning pressures
- Existing single-model methods like self-consistency struggle when the model's training data contains biases or gaps that lead to confident, repeated errors
- Reliable uncertainty estimation is needed to know when to trust model outputs, but single models often lack the diverse perspectives needed to flag their own blind spots
Concrete Example:
If a single model (e.g., Llama-2) mistakenly believes the capital of a country is City X due to training bias, it may generate City X in 90% of samples, leading to a high-confidence incorrect vote. A consortium including Mistral and Gemma might vote for the correct City Y or produce diverse answers, raising entropy and signaling a hallucination.
Key Novelty
Consortium Consistency (Consortium Voting + Consortium Entropy)
- Replaces single-model sampling with a 'consortium' of diverse LLMs (different architectures/training data) to generate the pool of candidate responses
- Calculates semantic entropy across the aggregated multi-model response set to better detect when models are 'confidently wrong' by leveraging disagreement between models
- Allocates the total response budget across multiple weaker/cheaper models to potentially outperform a single strong model at lower inference cost
Architecture
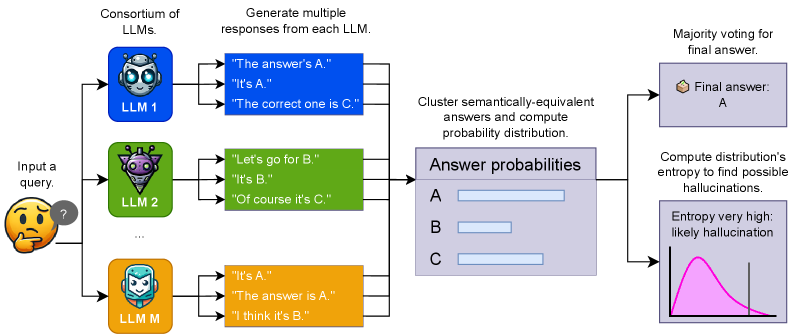
Illustration of the Consortium Consistency framework compared to single-model consistency.
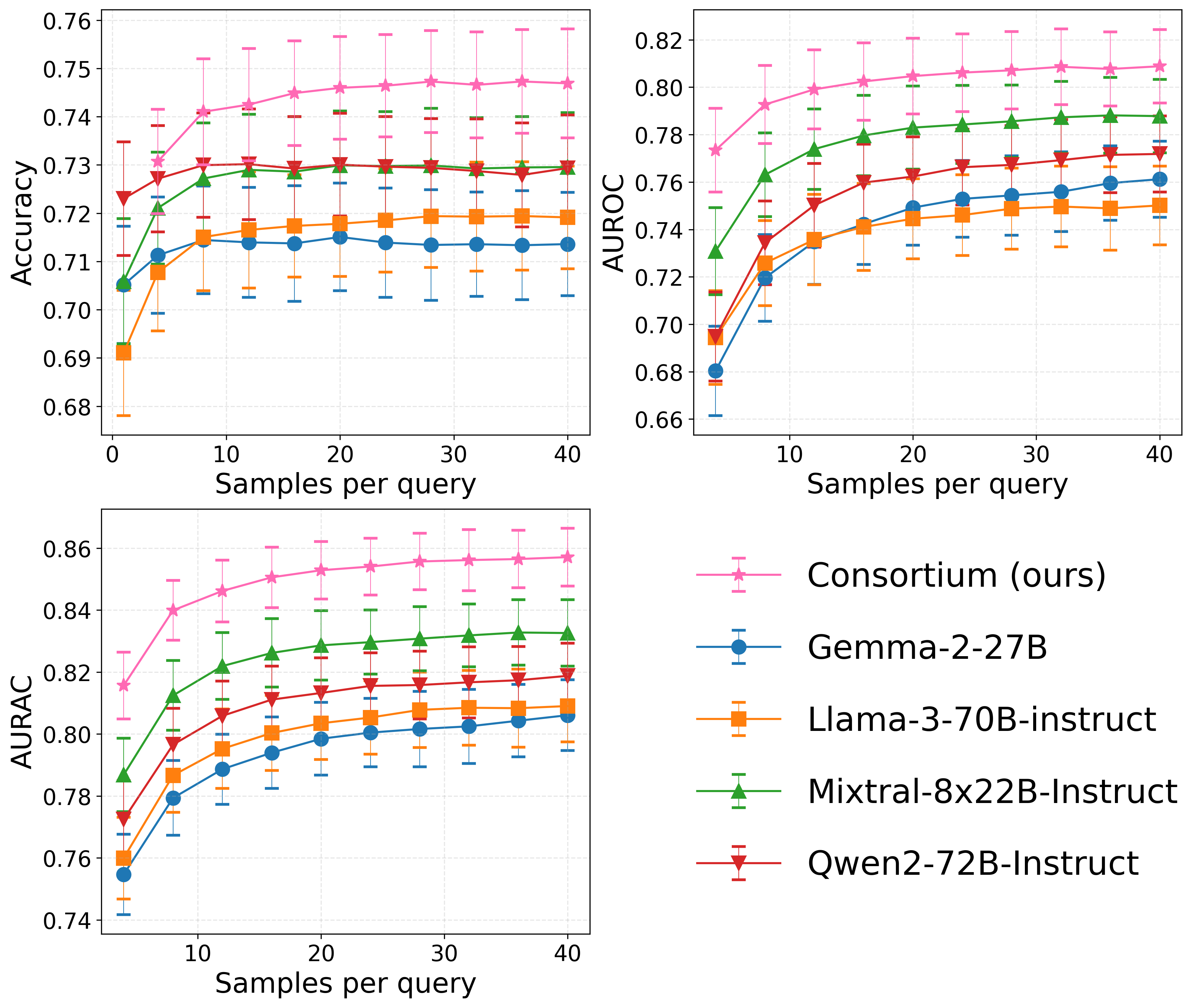
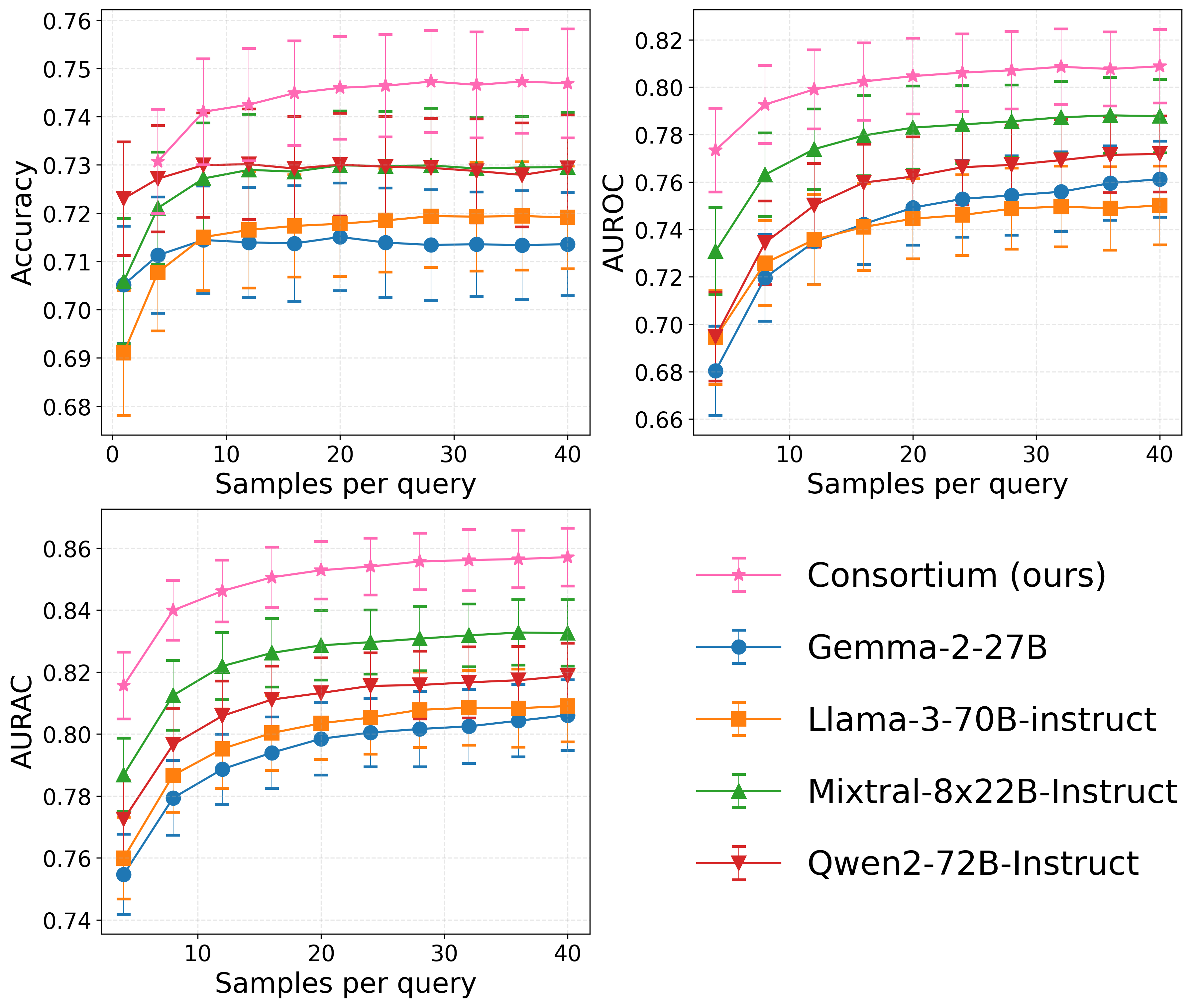
Evaluation Highlights
- Consortium consistency outperforms the 'hard baseline' (best single model in the group) in >92% of tested teams across accuracy, AUROC, and AURAC metrics
- Outperforms the 'standard baseline' (median single model) in >99% of cases across all metrics, showing robust improvements
- Achieves higher performance at lower inference cost: a consortium of mixed models dominates the cost-performance frontier compared to running the single strongest (and most expensive) model alone
Breakthrough Assessment
7/10
Strong empirical evidence that multi-model aggregation beats single-model baselines for reliability. While the idea of ensembling is classic, applying it specifically to semantic entropy for hallucination detection with a detailed cost/performance analysis is a valuable contribution.