📝 Paper Summary
Hallucination detection benchmark
Authentic user-LLM interaction analysis
AuthenHallu is a hallucination detection benchmark built entirely from naturally occurring LLM-human dialogues, revealing that real-world hallucinations differ significantly from those in artificially induced datasets.
Core Problem
Existing hallucination benchmarks rely on deliberately induced or simulated hallucinations, which fail to capture the complex distribution of genuine user queries and natural model errors found in real-world usage.
Why it matters:
- Artificial benchmarks (like HaluEval) force models to hallucinate, creating data distributions that deviate from how models actually behave in deployment
- Simulated benchmarks (like FELM) use simplified queries that lack the diversity and complexity of real human intent
- Trustworthy deployment requires evaluating detection systems on ecologically valid data where hallucinations emerge organically
Concrete Example:
In induced benchmarks, a model might be explicitly told 'write a plausible but incorrect answer.' In AuthenHallu, a user naturally asks a math problem, and the model attempts to solve it but fails (60% hallucination rate in math), reflecting a capability gap rather than instruction following.
Key Novelty
Ecologically Valid Hallucination Benchmarking
- Constructs the first hallucination benchmark derived entirely from the LMSYS-Chat-1M log of one million real-world conversations, rather than using synthetic prompts
- Employs a rigorous filtering and clustering pipeline to select 400 representative dialogues (800 pairs) covering diverse topics like Math, Coding, and Roleplay
- Provides granular human annotation for three hallucination types (Fact-conflicting, Input-conflicting, Context-conflicting) on authentic data
Architecture
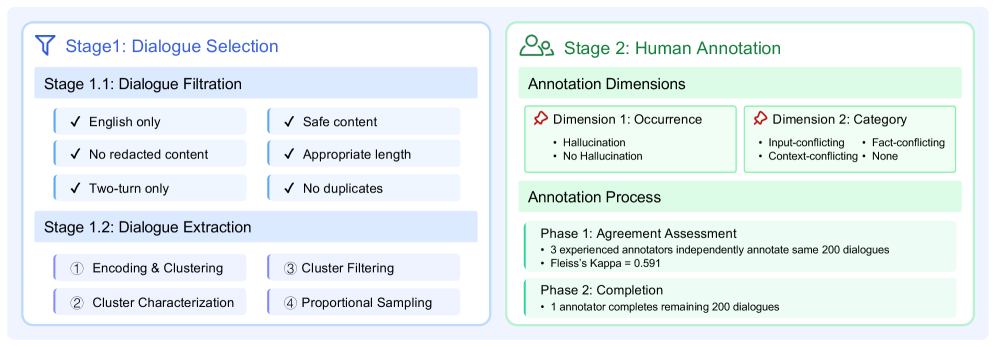
The construction pipeline of the AuthenHallu benchmark.
Evaluation Highlights
- 31.4% of authentic query-response pairs contain hallucinations, with fact-conflicting hallucinations being the most prevalent (62.5% of errors)
- Hallucination rates vary drastically by topic: 'Math & Number Problems' has the highest rate at 60.0%, followed by 'Dates, Time & Calendar' at 60.0%
- Vanilla LLMs (evaluated as detectors) perform insufficiently on authentic data, struggling to identify these naturally occurring errors
Breakthrough Assessment
8/10
Significant contribution by shifting the evaluation paradigm from synthetic/induced hallucinations to authentic wild data. Essential for realistic assessment, though the dataset size (800 pairs) is relatively small compared to synthetic ones.
