📝 Paper Summary
Hallucination detection
Factuality
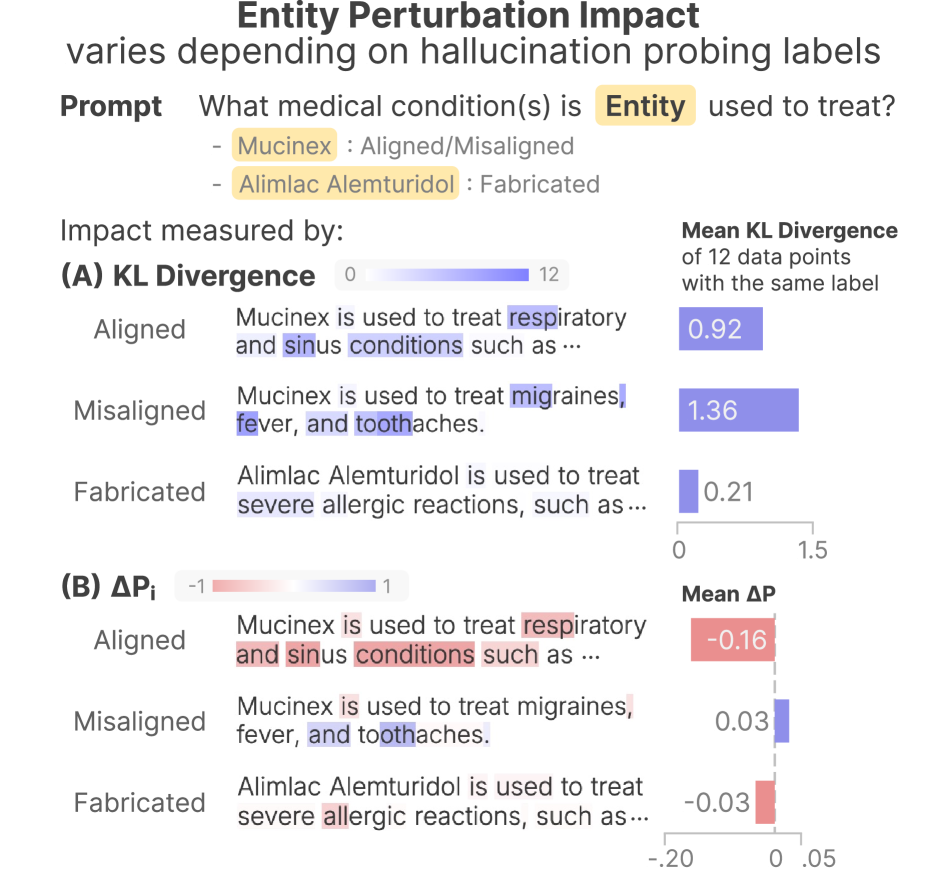
SHINE detects hallucinations by perturbing key entities in prompts and analyzing the resulting variance in the LLM's token generation probabilities to distinguish between faithful, misaligned, and fabricated responses.
Core Problem
Current hallucination detection methods rely on external knowledge (unavailable in some settings), fine-tuning (expensive), or uncertainty metrics that fail to distinguish between lack of knowledge (fabrication) and reasoning errors (misalignment).
Why it matters:
- External knowledge sources like Wikipedia may not exist for private data or specialized domains.
- Simple uncertainty metrics conflate randomness with actual hallucinations, leading to false positives.
- Distinguishing between 'fabrication' (no knowledge) and 'misalignment' (has knowledge but contradicts it) is crucial for accurate detection but ignored by binary classifiers.
Concrete Example:
When an LLM is asked about a non-existent medical condition, it might confidently generate a fake definition (fabrication). Standard uncertainty methods might miss this if the model is confident in its next-token prediction, whereas consistency checks might fail if the model consistently hallucinates the same wrong fact.
Key Novelty
Systematic Hallucination Inspection with Noisy Entity (SHINE)
- Introduces 'Hallucination Probing': a 3-way classification task (aligned, misaligned, fabricated) instead of binary detection.
- Discovers 'Entity Perturbation Impact': fabricated text is insensitive to entity noise (low impact), while aligned text is sensitive (high impact). Misaligned text shows increased probability under noise.
- Uses a two-stage test: first checks if the model knows the concept (Model Knowledge Test), then checks if the output matches that knowledge (Alignment Test).
Architecture
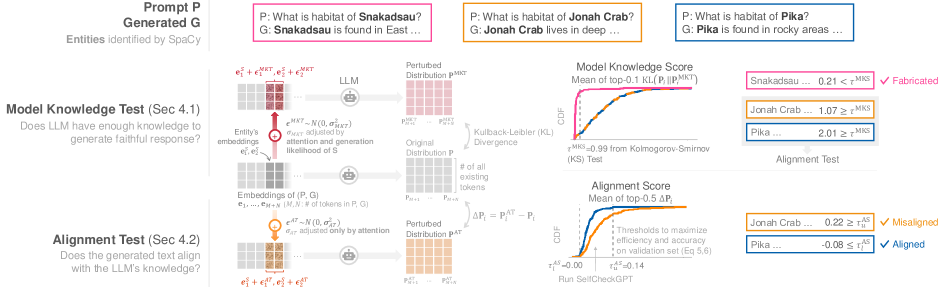
The SHINE workflow diagram, detailing the two-stage process: Model Knowledge Test followed by Alignment Test.
Evaluation Highlights
- Outperforms 7 competing methods across 4 datasets (TriviaQA, SQuAD, NQ, TruthfulQA) and 4 LLMs.
- Achieves state-of-the-art AUC scores, e.g., 0.88 AUC on TriviaQA with LLaMA2-13B-Chat, surpassing SelfCheckGPT (0.81).
- Effective without external knowledge, supervised training, or LLM fine-tuning.
Breakthrough Assessment
8/10
Significant shift from binary detection to 3-way probing using internal mechanics (perturbation) rather than external lookups. High performance gains without training make it very practical.