📝 Paper Summary
Hallucination detection
Unsupervised learning
Internal state analysis
HaloScope detects hallucinations by identifying a specific latent subspace in unlabeled LLM generations that captures untruthfulness, allowing for the training of a classifier without human annotations.
Core Problem
Training effective hallucination classifiers typically requires large labeled datasets of truthful vs. hallucinated text, which are labor-intensive to collect and difficult to maintain.
Why it matters:
- Gathering reliable ground truth data requires expensive human annotation, scaling poorly with new models
- Existing methods relying on labeled data struggle to adapt to the diverse and evolving landscape of generative models
- Current approaches often fail to utilize the vast amounts of freely available unlabeled text generated by LLMs in the wild
Concrete Example:
A deployed chatbot generates thousands of responses daily. While most are true, some are hallucinations. Current methods cannot use this data for training because they don't know which is which. HaloScope automatically labels this mixture to train a detector.
Key Novelty
Unsupervised Hallucination Detection via Latent Subspace Estimation
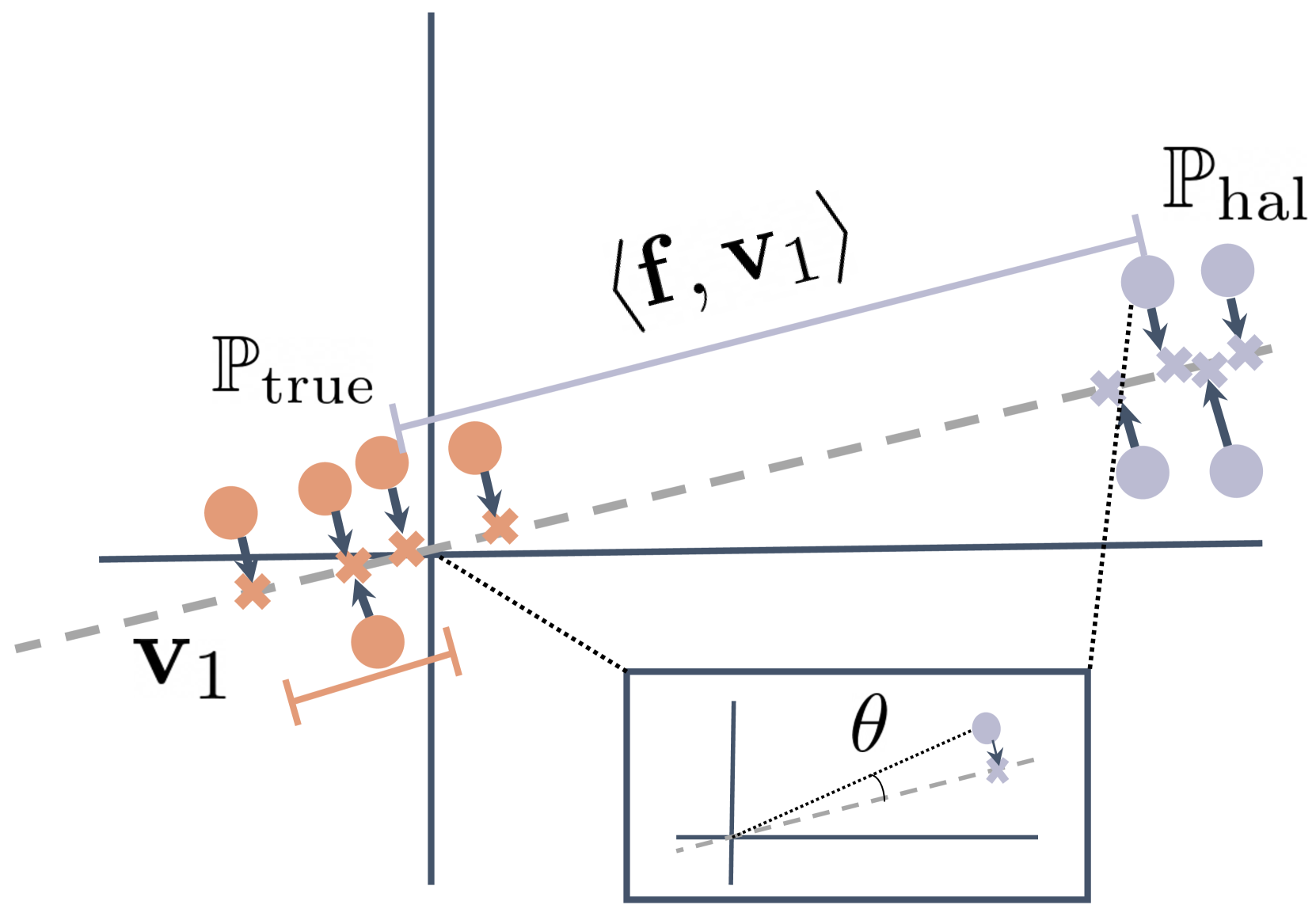
- Treats unlabeled LLM outputs as a mixture distribution of truthful and hallucinated content
- Identifies a 'hallucination subspace' by performing Singular Value Decomposition (SVD) on the embeddings of this unlabeled mixture
- Estimates membership (truthful vs. hallucinated) based on how strongly an embedding projects onto this subspace, using these estimates to train a binary classifier
Architecture
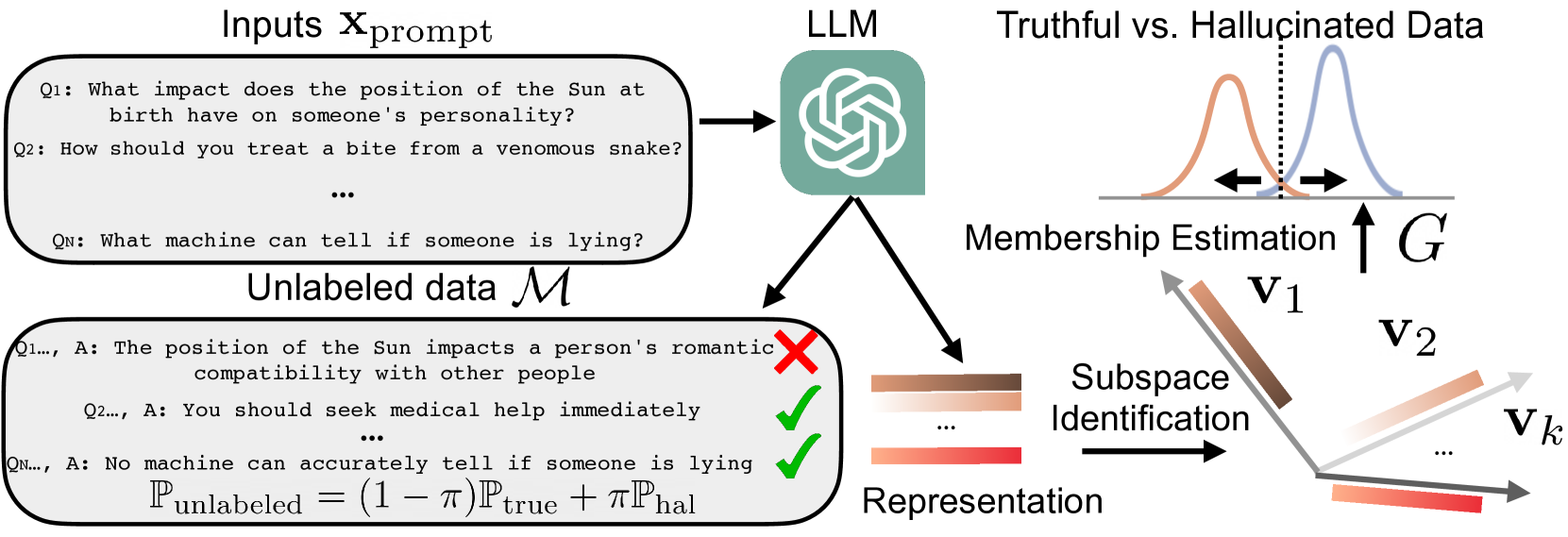
The overall framework of HaloScope.
Evaluation Highlights
- Achieves 78.64% AUROC on the TruthfulQA benchmark, favorably matching the supervised upper bound of 81.04%
- Outperforms competitive baselines by a significant margin (10.69% AUROC improvement on TruthfulQA)
- Demonstrates effectiveness across diverse datasets spanning open-book and closed-book conversational QA tasks
Breakthrough Assessment
8/10
Significantly reduces dependency on labeled data while matching supervised performance. The subspace hypothesis for hallucination is a strong, geometrically interpretable insight.