📝 Paper Summary
Hallucination detection
Uncertainty estimation
Mechanistic interpretability
LLMs possess an internal 'self-awareness' of whether they have seen a query during training and their likelihood of hallucinating, which can be predicted using a lightweight probe on the last token's hidden states.
Core Problem
LLMs often generate confident but factually incorrect responses (hallucinations) because they lack an explicit mechanism to express uncertainty or recognize when a query falls outside their training data knowledge.
Why it matters:
- LLMs are unreliable in real-world applications because they tend to be overconfident even when confabulating.
- Existing hallucination detection methods often rely on external reference texts or heavy sampling, rather than leveraging the model's own internal signals.
- Detecting hallucination risk *before* generation is critical for triggering mitigation strategies like refusal or Retrieval-Augmented Generation (RAG).
Concrete Example:
When asked about a news event from 2024 (unseen during training), a 2023-era LLM might confidently fabricate details instead of refusing. This paper shows the model's internal states actually encode the 'unseen' nature of the query, even if the generated text doesn't reflect it.
Key Novelty
Internal State Probing for Hallucination Risk
- Identifies specific neurons in the last layer of LLMs that activate differently for 'seen' vs. 'unseen' concepts and for high vs. low hallucination risk.
- Trains a lightweight MLP probe on the hidden states of the *query's last token* to predict hallucination status before the model generates a single word of the response.
Architecture
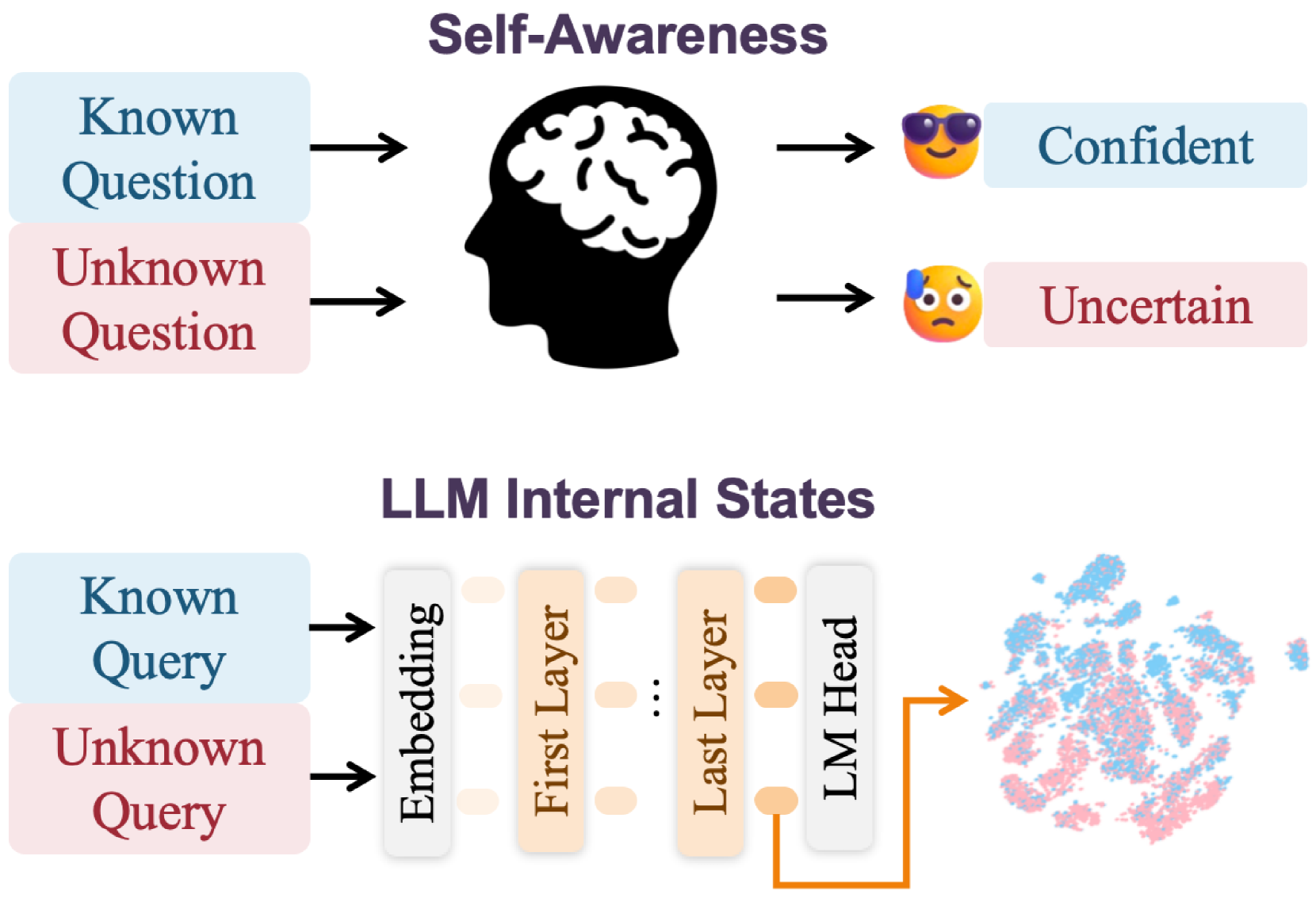
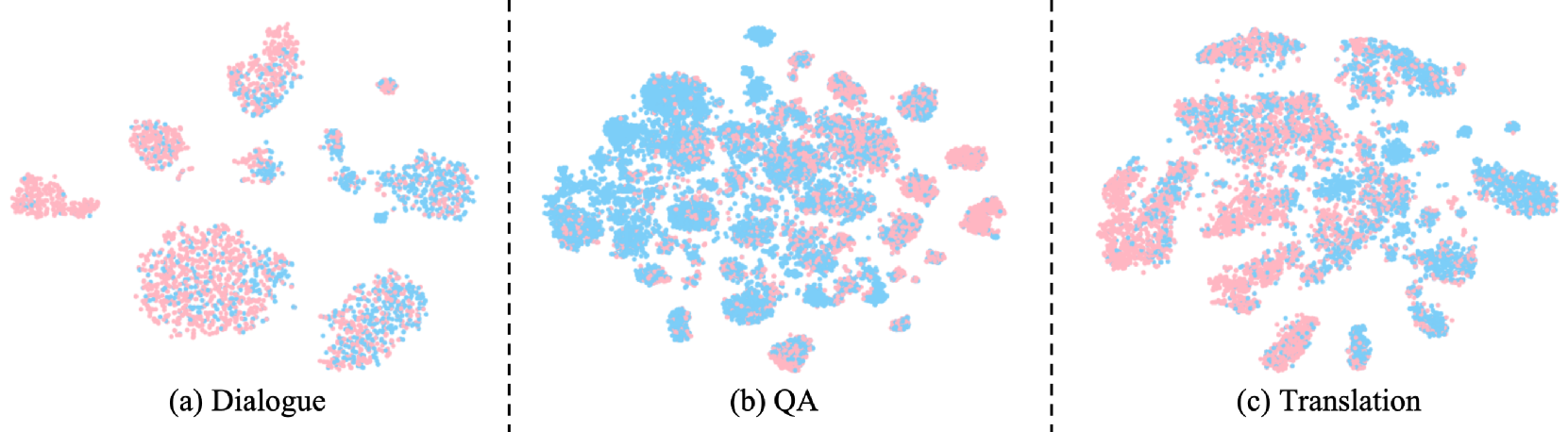
Conceptual comparison between human cognitive processes (recognizing unknown queries) and the proposed LLM internal state analysis. It illustrates the pipeline: Query -> LLM -> Internal State Extraction -> Estimator -> Risk Label.
Evaluation Highlights
- Achieves 84.32% average accuracy in estimating hallucination risk across 15 NLG tasks using Llama-2-7B's internal states.
- Detects whether a query was seen during training (2020 vs. 2024 news) with 80.28% accuracy.
- Outperforms perplexity-based baselines and self-check prompts (which ask the model 'can you answer this?') by significant margins.
Breakthrough Assessment
7/10
Strong empirical evidence that LLMs 'know what they don't know' at the representation level. The method is efficient (run-time probing) and effective, though primarily tested on Llama-2.